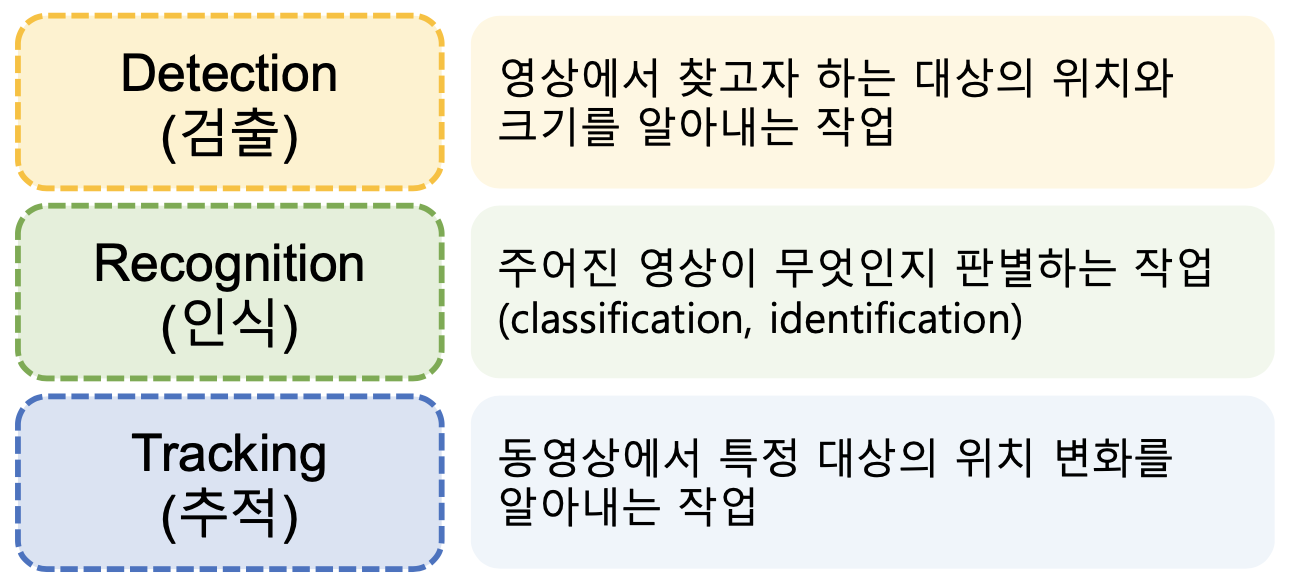
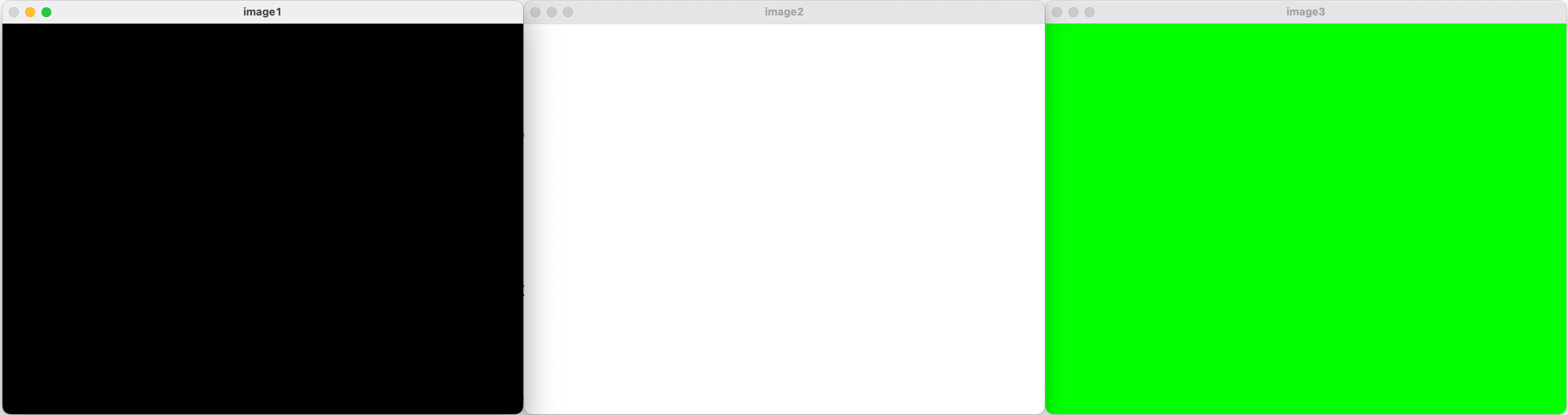
이번에는 이미지끼리 더해보겠습니다. 완전 다른 이미지 두 개를 더해줄 수도 있지만 쉬운 이해를 위해서 흰색 바탕에 검은색 원의 이미지를 생성해서 더해줘보겠습니다.
<코드>
import cv2
# 그레이스케일로 이미지 불러오기
src1 = cv2.imread('cat.jpg', cv2.IMREAD_GRAYSCALE)
src2 = cv2.imread('mask_circle.jpg', cv2.IMREAD_GRAYSCALE)
# 이미지 2개 더하기
dst = cv2.add(src1, src2)
cv2.imshow('dst', dst)
cv2.waitKey()
cv2.destroyAllWindows()
<실행 결과>
그레이스케일 영상에서 검은색은 0, 흰색은 255의 값을 가지므로, 검은색 원이 있던 부분은 원래의 고양이 사진을 그대로 출력하며, 흰색이었던 부분은 모두 흰색으로 출력되는 것을 확인 하실 수 있습니다. 참고로 두 이미지의 픽셀값을 더했을 때 255를 넘으면 모두 255(흰색)으로 출력됩니다.
src1 + src2
2. 가중치 덧셈
그렇다면 이미지를 각자 다른 비율로 더해주고 싶을 땐 어떻게 해야할까요? 그럴 땐 아래의 함수를 사용해주시면 됩니다.
코딩유치원에서는파이썬 기초부터사무자동화, 웹크롤링, 데이터 분석등의다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한전자공시시스템(DART)나텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.
시작하기에 앞서, OpenCV 라이브러리는 쥬피터 노트북에서 한줄한줄 실행하기 보다는 그냥 파이썬 파일(.py)에서 전체 코드를 실행하시는 것을 추천드립니다. imshow( )로 창을 띄우고 종료할 때 자꾸 파이썬 인터프리터가 먹통이 되더라구요.
참고로 이번 시간에는 카메라가 내장된 노트북이나 별도의 웹캠이 없으시다면 실습이 어렵답니다.
일단은 여러분들이 노트북을 가지고 코딩공부를 하고 계신다는 가정 하에 글을 작성하겠습니다.
1.OpenCV로 내장 카메라 영상 출력하기
이번 시간 가장 처음배워볼 것은 카메라 영상을 받아서 모니터에 띄워보는 것입니다.
복잡한 설명 없이 바로 코드를 실행해보겠습니다.
<코드>
# step1.opencv 라이브러리 불러오기
import cv2
# step2.카메라 열기 - 0은 기본 카메라를 의미
cap = cv2.VideoCapture(0)
# step3.무한 반복
while True:
# 카메라 연결 여부(True/False)와 현재 프레임 이미지를 읽음
retval, frame = cap.read()
# 만약 카메라가 연결되어 있지 않으면 while 반복문 종료
if retval == False:
break
# 'frame'이란 창 이름으로 현재 프레임 출력
cv2.imshow('frame', frame)
# 10초가 지나거나, ESC 키가 입력되면 while 반복문 종료
if cv2.waitKey(10) == 27:
break
# step4.카메라 닫고 모든창 종료
cap.release()
cv2.destroyAllWindows()
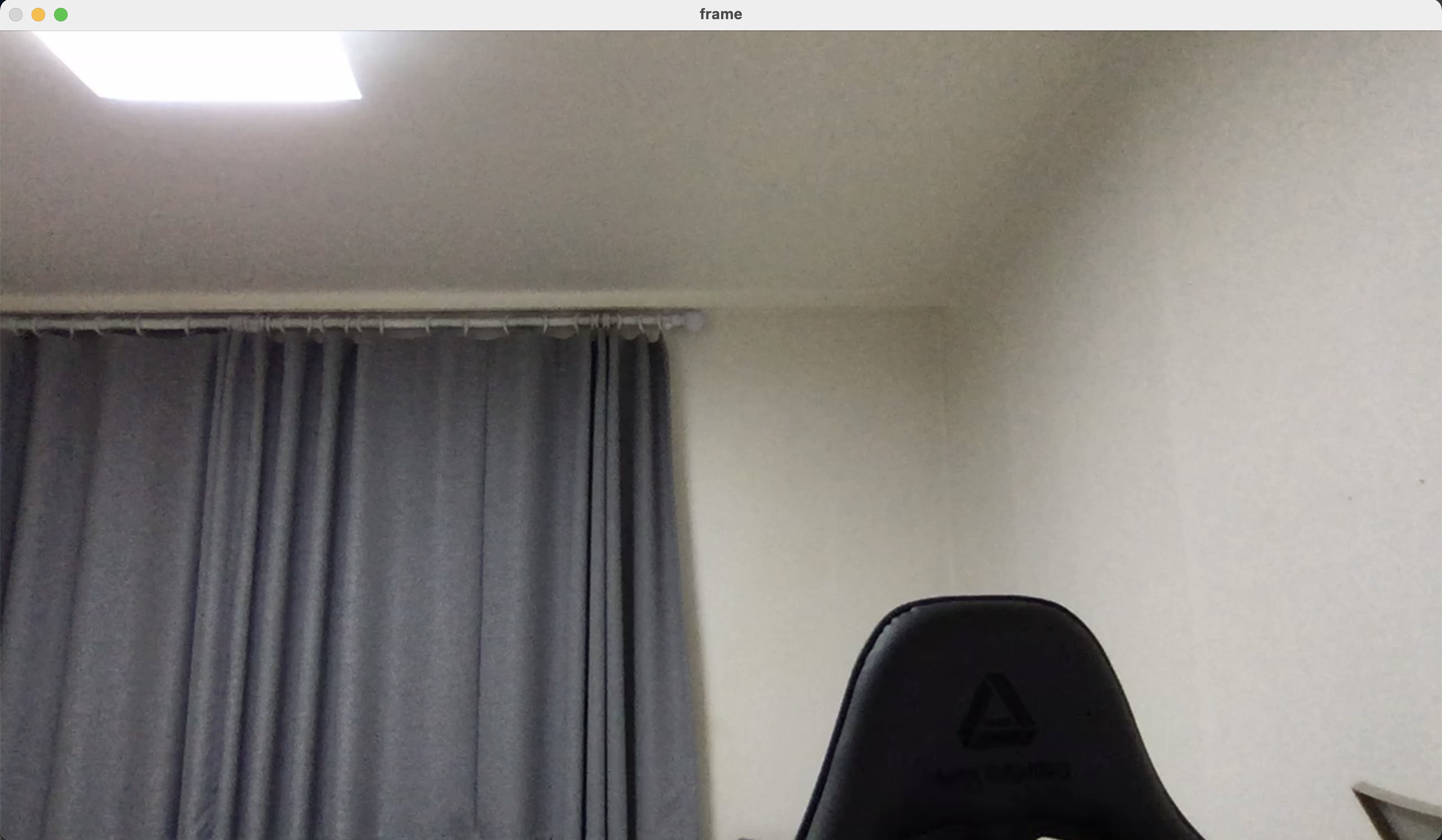
<실행 결과>
부끄러워서 숨어서 화면 캡쳐함
OpenCV에서는 카메라 영상과 이어서 배울 동영상 파일로부터 프레임(frame)을 받아오는 작업을 cv2.VideoCapture 클래스 하나로 처리합니다.
위의 코드에서는 cap이라는 변수로 cv2.VideoCapture 클래스를 객체화 해서 while 반복문 안에서 사용하고 있는 것을 보실 수 있을거예요.
참고로 cv2.VideoCapture(0)의 0은 기본 카메라를 의미하기 때문에 카메라가 한 대라면 그냥 고민 없이 0을 넣어 주시면 되고, 카메라가 두 대 이상이라면 장치관리자 표시되는 순서대로 1, 2를 입력해주시면 됩니다.
2.OpenCV로 동영상 파일 재생하기
위에서 말씀드렸 듯이 OpenCV를 이용해서 동영상 파일을 열 때도 cv2.VideoCapture 클래스를 이용합니다.
차이점은 cv2.VideoCapture( ) 안에 0 대신에 파일명을 넣어주면 됩니다.
아무 영상이나 아래의 사이트에서 다운로드 받으신 후에 적당한 파일명으로 저장해주세요. 물론 저장위치는 현재 작업경로에 넣어주시면 코딩하기 제일 편합니다.
만약 동영상을 그대로 재생하고 싶으시다면 방금 전 봤던 코드에서 한 줄만 바꿔주면 됩니다. 실행결과는 생략하도록 하겠습니다.
<코드>
# step1.opencv 라이브러리 불러오기
import cv2
# step2.동영상 파일 열기
cap = cv2.VideoCapture('하이랜드 소.mp4')
# step3.무한 반복
while True:
# 동영상 파일 존재 여부(True/False)와 현재 프레임 이미지를 읽음
retval, frame = cap.read()
# 만약 동영상 파일이 존재하지 않으면 while 반복문 종료
if retval == False:
break
# 'frame'이란 창 이름으로 현재 프레임 출력
cv2.imshow('frame', frame)
# 10초가 지나거나, ESC 키가 입력되면 while 반복문 종료
if cv2.waitKey(10) == 27:
break
# step4.동영상 파일 닫고 모든창 종료
cap.release()
cv2.destroyAllWindows()
3. 영상의 기본 정보 가져오기
이번에는 영상의 정보(영상의 프레임 사이즈, 전체 프레임수, FPS 등)를 가져오는 것을 배워보겠습니다. 이 내용은 카메라 영상과 동영상 파일 모두 적용 가능하지만, 저는 동영상 파일을 가지고 진행해보겠습니다.
<코드>
# step1.opencv 라이브러리 불러오기
import cv2
# step2.영상 파일 열기
cap = cv2.VideoCapture('하이랜드 소.mp4')
# step3.영상의 가로, 세로 사이즈, 전체 프레임수, FPS 등을 출력
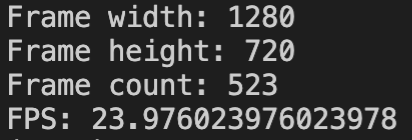
print('Frame width:', int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)))
print('Frame height:', int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
print('Frame count:', int(cap.get(cv2.CAP_PROP_FRAME_COUNT)))
print('FPS:', cap.get(cv2.CAP_PROP_FPS))
# step4.영상 닫고 모든창 종료
cap.release()
<실행결과>
더 많은 영상 정보는 아래의 OpenCV 공식 사이트를 참고하셔서 get( ) 괄호 안만 바꿔주시면 됩니다.
위에서 리스트를 이용해서 딕셔너리를 만드는 방법을 알아보았다면, 이제는 만든 딕셔너리를 사용하는 방법을 배워야겠죠?
이 부분은 딕셔너리 기초를 안다면 쉽게 이해할 수 있는 부분이므로 그냥 넘어가겠습니다.
# 제품 링크
key
# 제품 이름
dict_product[key][0]
# 제품 가격
dict_product[key][1]
4. 딕셔너리 응용 방법
아래의 코드는 특정 스마트스토어에서 새로 업로드 되는 제품만 텔레그램으로 전송받고자 했을 때 사용했던 코드입니다.
key에 저장된 제품 링크를 비교해서 새제품의 key : value만 필터링하여 저장 및 사용하기 위해서 딕셔너리를 사용하였죠. (글을 작성하면서 굳이 딕셔너리가 아니어도 zip 함수로 리스트를 만들고 인덱싱을 잘해주면 되겠다는걸 깨달았지만 그냥 넘어가도록 하겠습니다ㅎㅎ..)
위에서 만들었던 dict_product를 아래와 같이 딕셔너리 컴프리헨션과 결합하여 사용할 수 있답니다. 딕셔너리 컴프리헨션은 리스트 컴프리헨션을 알고계시다면 아주 쉽게 이해하실 수 있습니다.
new_products = {key:value for key, value in dict_product.items() if key not in old_products}
여기서 new_products에 저장된 값들은 for문을 이용해서 아래와 같이 가져올 수 있습니다.
<실제 응용 코드>
# 새로운 메시지가 있으면 링크 전송
if new_products:
for key in new_products:
bot.sendMessage(chat_id=chat_id,
text= new_products[key][0] +
'\n\n' + '가격:' + new_products[key][1] + '원' +
'\n\n' + key)
#step1.라이브러리 불러오기
import requests
from bs4 import BeautifulSoup as bs
import telegram
import schedule
import time
#step2.새로운 네이버 뉴스 기사 링크를 받아오는 함수
def get_new_products(old_products={}):
product_links = []
product_prices = []
product_names = []
# step3.for문을 이용해서 원하는 페이지에 접근, 정보 추출 후 리스트에 담기
for page_num in range(3): #여기서는 3번째 페이지까지만 크롤링 하도록 설정
# range를 이용하면 0부터 인덱스가 시작되므로 page_num에 1을 더해준 url을 이용
url = f'https://smartstore.naver.com/compuzone/category/ALL?st=RECENT&free=false&dt=IMAGE&page={page_num+1}&size=40'
# html 정보 받아와서 파싱
response = requests.get(url)
soup = bs(response.text , 'html.parser')
# css selector로 페이지 내의 원하는 정보 가져오기
# html_product_links = soup.select('a._3BkKgDHq3l.N=a:lst.product.linkAnchor') --> 잘 작동하지 않음
html_name = soup.select('strong.QNNliuiAk3')
html_price = soup.select('span.nIAdxeTzhx')
html_product_links = soup.select('li.-qHwcFXhj0 > a')
# 제품 이름 추출해서 리스트에 저장
for i in html_name:
product_names.append(i.get_text())
# 제품 가격 추출해서 리스트에 저장
for i in html_price:
product_prices.append(i.get_text())
# 제품 링크 추출해서 리스트에 저장
for i in html_product_links:
product_links.append('https://smartstore.naver.com' + i.attrs['href'])
# 제품 링크를 key, 제품이름과 가격을 value로 dictonary 만듦
dict_product = dict(zip(product_links, zip(product_names, product_prices)))
# 기존의 링크와 신규 링크를 비교해서 새로운 링크만 저장
new_products = {key:info for key, info in dict_product.items() if key not in old_products}
return new_products
#step3.새로운 네이버 뉴스 기사가 있을 때 텔레그램으로 전송하는 함수
def send_products():
# 함수 내에서 처리된 리스트를 함수 외부에서 참조하기 위함
global old_products
# 위에서 정의했던 함수 실행
new_products = get_new_products(old_products)
# 새로운 메시지가 있으면 링크 전송
if new_products:
for key in new_products:
bot.sendMessage(chat_id=chat_id,
text= new_products[key][0] +
'\n\n' + '가격:' + new_products[key][1] + '원' +
'\n\n' + key)
else:
# bot.sendMessage(chat_id=chat_id, text="새로운 제품이 없습니다.") --> 잘 실행되는지 확인하고 싶으면 pass 대신 활성화
pass
# 기존 제품 정보를 계속 축적하기 위함
old_products.update(new_products)
# 실제 프로그램 구동
if __name__ == '__main__':
#토큰을 변수에 저장
bot_token ='자신의 텔레그램 봇 토큰 번호'
bot = telegram.Bot(token = bot_token)
# 자신의 봇의 chat_id
chat_id = '1516137537'
#위에서 얻은 chat id로 bot이 메세지를 보냄.
bot.sendMessage(chat_id = chat_id, text="컴퓨존의 새제품 실시간 크롤링이 시작 되었습니다")
# #step5.기존에 보냈던 링크를 담아둘 리스트 만들기
old_products = {}
# 가장 처음 실행 시, 한 번만 old_products에 제품 링크들 저장
old_products = get_new_products(old_products)
# 주기적 실행과 관련된 코드 (hours는 시, minutes는 분, seconds는 초)
job = schedule.every(10).seconds.do(send_products)
while True:
schedule.run_pending()
time.sleep(1)
오늘은 for 반복문 안에서 리스트 컴프리헨션을 사용할 때 주의할 점에 대해서 말씀드리려 합니다.
1. 리스트 컴프리헨션을 사용하는 이유
저는 리스트 컴프리헨션 문법을 웹크롤링을 하면서 자주 사용해 왔습니다. 어떤 값을 하나씩 리스트에 추가해줄 때 아주아주 유용하기 때문입니다.
<리스트 컴프리헨션을 사용하지 않은 코드>
new_contents=[]
for content in contents:
if content not in old_contents:
new_contents.append(content)
<리스트 컴프리헨션을 사용한 코드>
new_contents = [content for content in list_contents if content not in old_contents]
4줄의 코드가 이렇게 간단해 지니깐 안 쓸 이유가 없겠죠?
2. for문 안에서 리스트 컴프리헨션을 사용하지 않은 이유
하지만 최근 프로젝트에서 아래와 같이 리스트 컴프리헨션 문법을 사용하지 않았답니다.
그 이유는 for문을 돌 때 마다 리스트가 초기화 되어 버리기 때문이었습니다.
# 제품명을 담을 빈 리스트 선언
product_name = []
# for문을 이용해서 원하는 페이지에 접근, 정보 추출 후 리스트에 담기
for page_num in range(3):
url = f'https://smartstore.naver.com/compuzone/category/ALL?st=RECENT&free=false&dt=IMAGE&page={page_num+1}&size=40'
response = requests.get(url)
soup = bs(response.text , 'html.parser')
# css selector로 페이지 내의 원하는 정보 가져오기
html_product = soup.select('strong.QNNliuiAk3')
# 텍스트만 추출
for i in html_product:
product_name.append(i.get_text())
무슨 말인지 아직 감이 안오신다면 for문 밖에 product_name 리스트가 밖에서 선언된 것에 주목해보세요.
저의 목적은 for문을 돌면서 1, 2, 3페이지에 접속하고, 각 페이지에서 필요한 자료를 리스트에 계속 추가하는 것이었습니다.
하지만 아래와 같이 리스트 컴프리헨션 문법을 사용해버리면 product_name이라는 이름의 리스트를 for문 안에서 매번 새로 선언되어서 그 전에 쌓여있던 요소들이 모두 삭제되어 버립니다.
# for문을 이용해서 원하는 페이지에 접근, 정보 추출 후 리스트에 담기
for page_num in range(3):
url = f'https://smartstore.naver.com/compuzone/category/ALL?st=RECENT&free=false&dt=IMAGE&page={page_num+1}&size=40'
response = requests.get(url)
soup = bs(response.text , 'html.parser')
# css selector로 페이지 내의 원하는 정보 가져오기
html_product = soup.select('strong.QNNliuiAk3')
# 리스트 컴프리헨션 사용
product_name = [i.get_text() for i in html_product]
글을 마치며,
이번 글은 누군가가에게는 당연한 이야기를 뭐 이렇게 길게 써놨는가 싶을 수 있겠지만, 코딩유치원의 취지에 잘 맞는 글이라고 생각이 듭니다.
아직 모르는 것이 많은 초보에게는 작은 돌뿌리도 큰 바위처럼 느껴지기 때문이죠.
코딩유치원생 여러분들은 코딩을 하시다가 모르는 부분이 생기시면 주저하지 마시고, 댓글 달아주세요.
# step1.라이브러리 불러오기
import requests
from bs4 import BeautifulSoup as bs
import telegram
import time
import pandas as pd
# step2.제품명과 제품가격정보를 담을 빈 리스트 선언
product_name = []
product_price = []
# step3.for문을 이용해서 원하는 페이지에 접근, 정보 추출 후 리스트에 담기
for page_num in range(3):
# range를 이용하면 0부터 인덱스가 시작되므로 page_num에 1을 더해준 url을 이용
url = f'https://smartstore.naver.com/compuzone/category/ALL?st=RECENT&free=false&dt=IMAGE&page={page_num+1}&size=40'
# html 정보 받아와서 파싱
response = requests.get(url)
soup = bs(response.text , 'html.parser')
# css selector로 페이지 내의 원하는 정보 가져오기
html_product = soup.select('strong.QNNliuiAk3')
html_price = soup.select('span.nIAdxeTzhx')
# 텍스트만 추출
for i in html_product:
product_name.append(i.get_text())
for i in html_price:
product_price.append(i.get_text())
# step4.zip 모듈을 이용해서 list를 묶어주기
list_sum = list(zip(product_name, product_price))
# step5.데이터프레임의 첫행에 들어갈 컬럼명
col = ['제품명','가격']
# step6.pandas 데이터 프레임 형태로 가공
df = pd.DataFrame(list_sum, columns=col)
# step7.엑셀에 저장
df.to_excel('컴퓨존 제품 목록.xlsx')
5.실행 결과
한 페이지에 40개의 품목이 있으니, 정확히 3개의 페이지에서 모든 제품명과 가격 정보를 크롤링해서 엑셀로 저장한 것을 확인할 수 있습니다.
위에서 언급했던 공개 소프트웨어 라이선스의 두 가지 종류에 대해서 조금 더 자세히 알아보겠습니다.
1) GPL
기본적으로 어떤 프로그램을 개발할 때, GPL 코드를 일부라도 사용하게 되면 그 프로그램은 GPL이 됩니다. GPL을 가진 프로그램을 유료로 판매하는 것은 가능하지만, 반드시 전체 소스코드는 무료로 공개해야 합니다.
GPL 코드를 사용한 SW를 내부적인(개인, 기관, 단체 등) 목적으로만 사용할 때에는 소스코드를 공개할 필요가 없지만 어떤 형태로든(유료든 무료든) 외부에 공표/배포할 때에는 전체 소스코드를 공개해야 합니다.
2) LGPL
LGPL(Lesser General Public License)는 GPL보다 훨 씬 완화된 라이선스 방식입니다.
가장 큰 차이점은 LGPL 코드를 정적(static) 또는 동적(dynamic) 라이브러리로 사용한 프로그램을 개발하여 판매/배포할 경우에 프로그램의 소스코드를 공개하지 않아도 된다는 점입니다. LGPL 코드를 사용했음을 명시만 하면 된다고 하는데 어떻게 명시해야하는지는 아직 잘 모르겠네요.
여기서 주의할 점은, LGPL 코드를 단순히 이용하는 것이 아니라 이를 수정한 또는 이로부터 파생된 라이브러리를 개발하여 배포하는 경우에는 전체 코드를 공개해야 한다는 것입니다.
4.동적 로드 라이브러리 vs 정적 라이브러리
세상에.. 공부하면 할 수록 모르는 것 투성이네요. 위에서 LGPL을 설명하면서 나왔던 정적, 동적 라이브러리에 대해서 잠시 다루어보겠습니다. 여기서 말하는 라이브러리는 함수, 구조체, 클래스 등을 포함하고 있는 컴파일된 파일을 의미합니다.
1) 정적 라이브러리(Static Library)
프로그램 빌드 시, 라이브러리를 실행 코드에 넣는 방식을 의미합니다. 이 방식의 장점은 별도 외부 파일이 필요없이 단일 어플리케이션으로 사용가능하다는 것이며, 단점은 로딩하는데에 무겁다는 것입니다.
확장자는 윈도우에서는 .lib이며, 리눅스에서는 .a입니다.
2) 동적 로드 라이브러리(Dynamic Load Library)
동적 로드 라이브러리는 쉽게 말해서 외부에 라이브러리 파일을 두고, 그때 그때 그 안의 내용물을 불러와서 사용하는 방식입니다. 그렇기 때문에 정적 라이브러리와 반대로 로딩이 빠른 대신에, 반드시 라이브러리 파일을 함께 배포해야 하는 불편함이 있습니다.
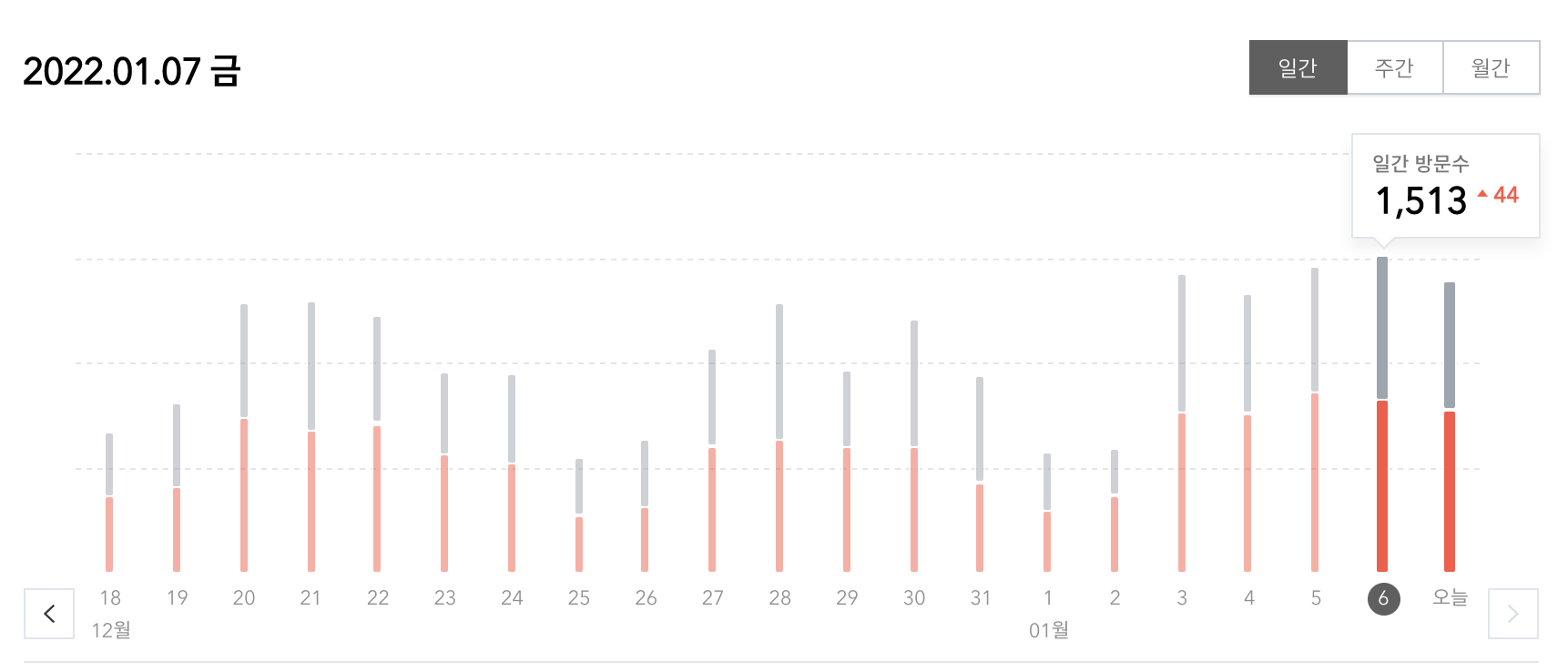
이번 시간에는 문단을 정렬하는 방법과 표의 셀 안의 내용을 정렬하는 방법에 대해서 공부해보겠습니다.
문단 정렬셀 정렬
실습을 위해서 '파이썬으로 MS워드 문서 다루기 3편'에서 사용했던 예제 문서를 사용하도록 하겠습니다.
3편을 보지 않고 오신분은 아래의 코드를 실행하시면 예제 문서가 자동으로 생성될 거예요.
from docx import Document
document = Document()
document.add_heading('코딩유치원 python-docx 강의', level = 0)
p = document.add_paragraph('안녕하세요, 코린이 여러분!')
p.add_run(' 코딩유치원에 오신 것을 환영합니다.').bold = True
document.add_paragraph('문장 추가 1')
document.add_paragraph('문장 추가 2')
document.add_paragraph('문장 추가 3')
document.add_paragraph('문장 추가 4')
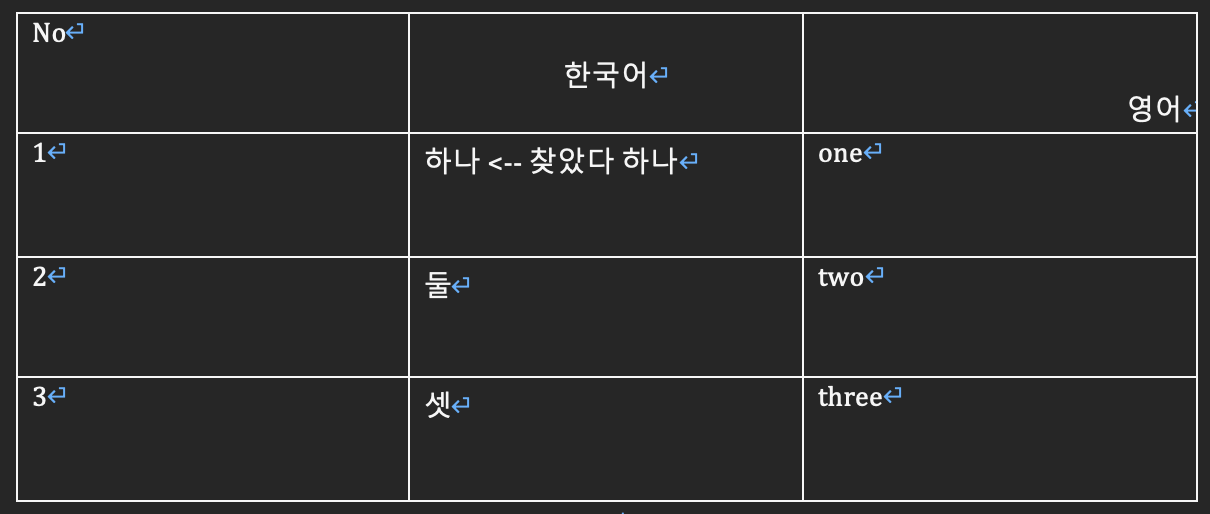
records = (
(1, '하나', 'one'),
(2, '둘', 'two'),
(3, '셋', 'three')
)
table = document.add_table(rows=1, cols=3)
# 만든 표의 스타일을 가장 기본 스타일인 'Table Grid'로 설정
table.style = document.styles['Table Grid']
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'No'
hdr_cells[1].text = '한국어'
hdr_cells[2].text = '영어'
for qty, id, desc in records:
row_cells = table.add_row().cells
row_cells[0].text = str(qty)
row_cells[1].text = id
row_cells[2].text = desc
document.save('예제 문서.docx')
1. 문단 정렬
가장 처음 배울 내용은 우리가 자주 사용하는 왼쪽, 오른쪽, 가운데, 양쪽 정렬을 적용하는 방법입니다.
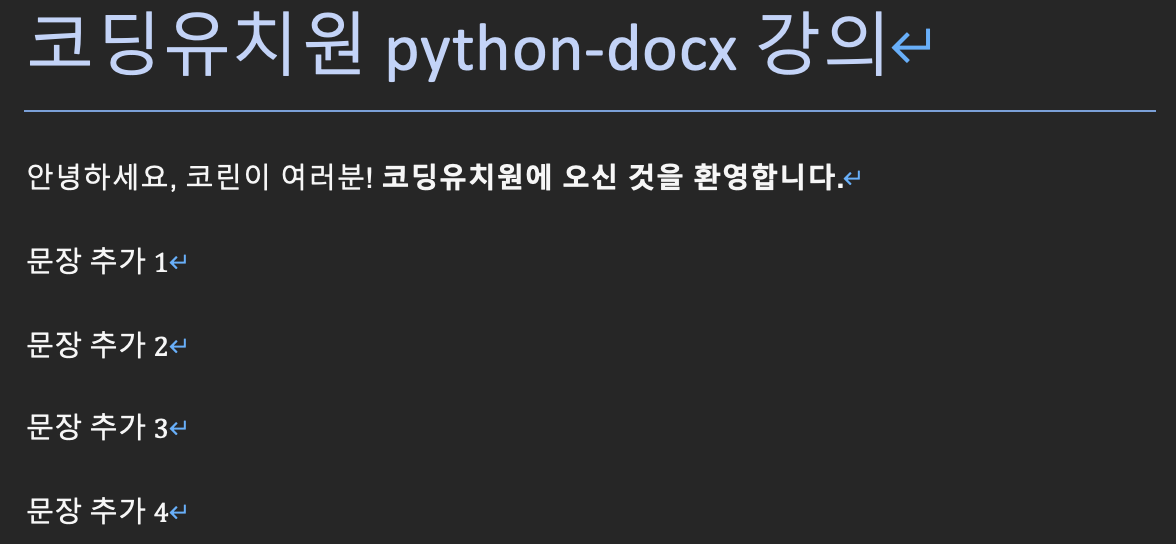
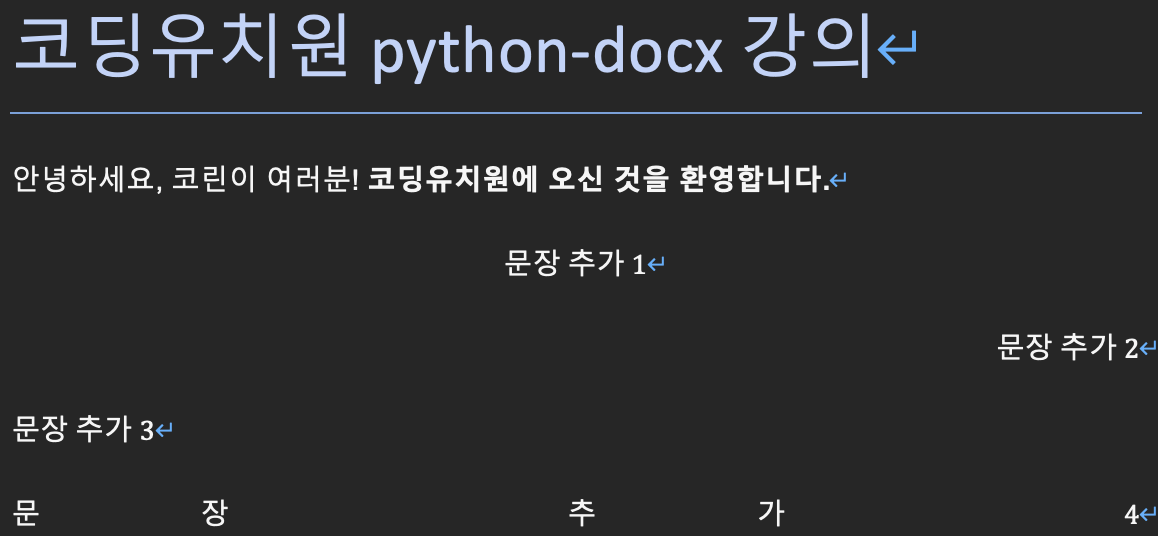
적용 전과 적용 후의 문단 상태를 비교해보세요. 아시겠지만 paragraphs[0]이 첫번째 문단이므로 두번째 문단부터 적용한 것이랍니다.
from docx import Document
from docx.enum.text import WD_ALIGN_PARAGRAPH
document = Document('예제 문서.docx')
# 왼쪽 정렬
paragraph1 = document.paragraphs[1]
paragraph1.alignment = WD_ALIGN_PARAGRAPH.LEFT
# 가운데 정렬
paragraph2 = document.paragraphs[2]
paragraph2.alignment = WD_ALIGN_PARAGRAPH.CENTER
# 오른쪽 정렬
paragraph3 = document.paragraphs[3]
paragraph3.alignment = WD_ALIGN_PARAGRAPH.RIGHT
# 양쪽 정렬
paragraph4 = document.paragraphs[4]
paragraph4.alignment = WD_ALIGN_PARAGRAPH.JUSTIFY
# 텍스트 배분 (글자를 흩어서 배치)
paragraph_last = document.paragraphs[-1] # 마지막 문단
paragraph_last.alignment = WD_ALIGN_PARAGRAPH.DISTRIBUTE
# 현재 작업경로에 저장
document.save('예제 문서.docx')
<기존 예제 문서>
<정렬 후 예제 문서>
2. 셀 정렬
워드에서 표, 정확히는 셀 안의 내용들을 정렬하는 방법을 공부해 보겠습니다.
셀 정렬은 크게 수평 정렬과 수직 정렬로 나뉩니다.
1) 수평 정렬
먼저 예제 문서의 첫번째 열에 수평 정렬(좌측, 가운데, 우측)을 적용해보겠습니다. 공식 문서에서는 table 객체에다가 .alignment를 하라고 되어 있지만 해본 결과 되지 않는 것을 확인했습니다.
꼭 paragraphs 객체에 정렬을 적용해주세요.
from docx.enum.table import WD_TABLE_ALIGNMENT
document = Document('예제 문서.docx')
# LEFT : 왼쪽 정렬, CENTER: 가운데 정렬, RIGHT: 오른쪽 정렬
document.tables[0].rows[0].cells[0].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.LEFT
document.tables[0].rows[0].cells[1].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.CENTER
document.tables[0].rows[0].cells[2].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.RIGHT
# 현재 작업경로에 저장
document.save('예제 문서.docx')
<실행 결과>
2) 수직 정렬
수직 정렬은 위에서 배운 수평 정렬이 paragraphs 객체에 적용한 것과 다르게 cells 객체에 적용해야 합니다.
(이 부분도 공식문서에 틀리게 작성되어 있어서 알아내느라 고생했네요ㅜㅜ)
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT
document = Document('예제 문서.docx')
# LEFT : 위쪽 정렬, CENTER: 가운데 정렬, RIGHT: 아래쪽 정렬
document.tables[0].rows[0].cells[0].vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.TOP
document.tables[0].rows[0].cells[1].vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
document.tables[0].rows[0].cells[2].vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.BOTTOM
# 현재 작업경로에 저장
document.save('예제 문서.docx')
from docx import Document
# 새로운 문서 만들기
doc = Document()
#스타일 적용하기
style = document.styles['Normal']
font = style.font
font.name = 'Arial'
para = doc.add_paragraph('Some text\n')
위의 방법은 add_paragraph에도 적용할 수 있고, 위와 아래의 방법모두 add_run으로 쓰인 문장에 적용 가능합니다.
<선 문단 입력, 후 스타일 적용>
para.add_run('코딩유치원에 오신 것을 환영합니다.').bold = True
run = doc.paragraphs[0].runs[0]
run.font.name = 'Arial'
여기서 조금 불편한 점은 한글은 위의 방식으로 폰트 적용이 안되어서 다른 방법을 사용해야한다는 것입니다.
doc = Document('test.docx')
from docx.oxml.ns import qn
style = doc.styles['Normal']
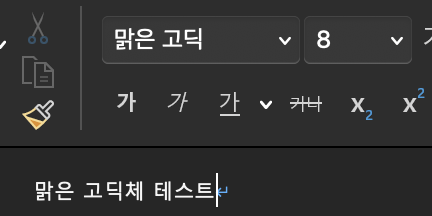
style._element.rPr.rFonts.set(qn('w:eastAsia'), '맑은 고딕')
style.font.name = '맑은 고딕'
style.font.size = Pt(8)
para = doc.add_paragraph('맑은 고딕체 테스트')
# 저장
doc.save('test.docx')
2.크기
문자 크기를 변경하기 위해서는 우선 아래와 같이 폰트 크기와 관련된 클래스를 import 해주어야 합니다.
from docx.shared import Pt
다음으로는 run 객체를 지정해주어야 하는데요. 저는 문단(paragraphs) 안의 모든 run 객체를 바꿔주는 코드를 짜보았습니다.
# 첫번째 문단의 문장(run)들을 리스트로 받기
para1 = doc.paragraphs[0].runs
# for 문을 이용해서
for run in para1:
run.font.size = Pt(20)
<동작 확인용 샘플코드>
from docx import Document
from docx.shared import Pt
doc = Document()
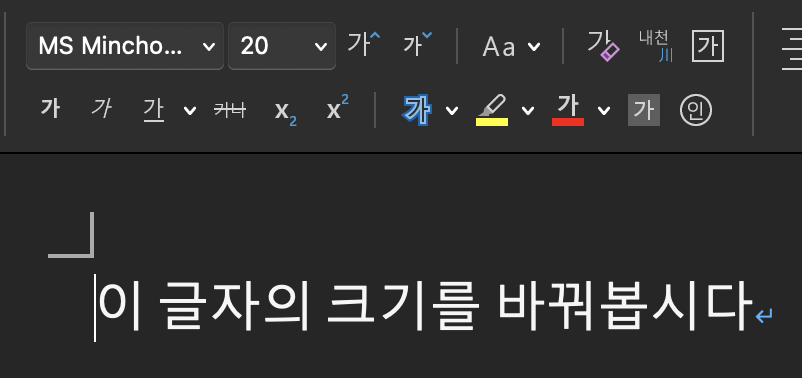
para = doc.add_paragraph('이 글자의 크기를 바꿔봅시다')
# 첫번째 문단의 문장(run)들을 리스트로 받기
para = doc.paragraphs[0].runs
# for 문을 이용해서
for run in para:
run.font.size = Pt(20)
# 저장
doc.save('test.docx')
<실행 결과>
3. 색깔
문자 색깔을 변경하기 위해서는 RGBColor 클래스를 import 해주어야 합니다.
from docx.shared import RGBColor
그 다음엔 문단을 하나 추가하고, 추가한 문단의 첫 문장을 run 객체로 선언해줍니다.
사실 paragraph를 생성하면 자동으로 run 객체를 생성하고 그것으로 문장을 써주는 개념이랍니다. 그래서 아래와 같이 add_run( )으로 문장을 써준 것이 아님에도 para2가 runs[0]를 가질 수 있는 것이죠.
para2 = doc.add_paragraph('글자 색깔을 바꿔봅시다')
run = para2.runs[0]
font = run.font
# RGB 컬러를 각각 16진수로 표현 (R, G, B)
font.color.rgb = RGBColor(0xFF, 0x24, 0xE9)
# 저장
doc.save('test.docx')