안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

오늘은 어제 오늘 도전해봤던 코스피, 코스닥 상장기업 영업이익 성장세로 필터링 해보기 프로젝트를 중간 정리하는 시간을 가져보겠습니다.
모두 완료하고 포스팅을 해보려 했으나, 부족한 실력으로 인해서 시간이 조금 더 걸릴 듯해서 중간 정리 글을 써보려 합니다.
1. 프로젝트에 사용된 패키지
우선 사용한 패키지는 예전에 소개드렸던 dart-fss 패키지입니다.
<DART-FSS 관련 지난 글>
2021.06.10 - [파이썬 패키지/전자공시시스템(DART)] - [Python/Dart] 파이썬으로 공시 정보 가져오기 1편_ DART API와 DART-FSS 패키지 소개
2021.06.22 - [파이썬 패키지/전자공시시스템(DART)] - [Python/Dart] 파이썬으로 공시 정보 가져오기 2편_ 상장된 회사 재무제표 EXCEL로 저장하기
2021.06.25 - [파이썬 패키지/전자공시시스템(DART)] - [Python/Dart] 파이썬으로 공시 정보 가져오기 3편_특정회사 혹은 특정 공시유형 가져오기
2021.06.27 - [파이썬 패키지/전자공시시스템(DART)] - [Python/Dart] 파이썬으로 공시 정보 가져오기 4편_재무제표 4종 골라서 DataFrame으로 추출하기(ft. 재무상태표, 손익계산서, 포괄손익계산서, 현금흐름표)
2021.06.27 - [파이썬 패키지/전자공시시스템(DART)] - [Python/Dart] 파이썬으로 공시 정보 가져오기 5편_dart-fss 재무제표 다운로드 안될 때 해결법
2021.06.30 - [파이썬 패키지/주식투자] - [Python/Dart] 파이썬으로 공시 정보 가져오기 6편_XBRL 데이터 추출(ft. 제무재표, 감사 정보, 작성자 정보, 공시문서 정보 등등)
공부하면서 느꼈지만 해당 패키지는 하나의 목적을 이루기 위한 방법이 여러 루트가 있어서 조금 정리를 할 필요가 있다고 느꼈습니다.
2. 프로젝트의 목적
프로젝트의 목적은 다음과 같습니다.
주식 시장에 상장된 모든 기업들을 살펴보기엔 시간은 한정적입니다. 그래서 원하는 재무상태나 매출/영업이익의 증가세를 가진 기업들을 공시정보를 토대로 필터링하여 엑셀로 저장하고, 이 정보를 투자 판단에 활용하는 것이 프로젝트의 목적입니다.
참고로, 이번 프로젝트에서는 dart-fss 패키지만으로도 충분하지만, 추후에 회사의 현금 및 환금성 높은 자본과 현재의 시가총액을 비교하는 프로젝트를 해볼 때에는 FinanceDataReader 패키지도 함께 다루어 볼 예정입니다.
일단 이번 프로젝트는 모든 코스피 상장 기업의 가장 최근 사업보고서(연간)를 가져와서 3년간 영업이익을 비교하고, 3년간 계속 상승했다면 해당 기업의 이름을 저장하는 것을 목표로 할 것입니다.
3. 프로젝트의 컨셉 및 장애요소
프로젝트의 큰 그림을 그려보겠습니다. 대략적인 컨셉이며 추후에 조금 변경될 수도 있습니다.
1) 상장회사 리스트 불러오기
# DART 에 공시된 회사 리스트 불러오기 corp_list = dart.get_corp_list()
2) 코스피 상장사의 회사코드와 회사명 각각 리스트에 저장
# 전체 상장기업 리스트 중 코스피만 골라서 담기 kospi_list = corp_list.find_by_sector(sector='', market='Y')여기서 kospi_list는 821개의 요소를 가지는데, 네이버 증권에서 코스피 탭을 들어가보면 1730개가 뜸.
(이건 정확히 무슨 차이인지 확인해볼 필요가 있음)
<네이버 증권_코스피 종목>
https://m.stock.naver.com/index.html#/domestic/capitalization/KOSPI
3) for문으로 회사코드를 모두 참조하며, xbrl 다운로드
- 기업이 아닌 펀드 종목의 경우엔 xbrl이 없으므로 예외처리(try, except)
- ex. 한국ANKOR유전, 베트남개발1 등등
4) 다운받은 xbrl에서 연결/개별 재무제표 여부 판단
- xbrl.exist_consolidated( )로 True/False 리턴 받아서 if/else문
- 쉽게 요약하면, 자회사가 있으면 연결 재무제표, 없으면 개별 재무제표
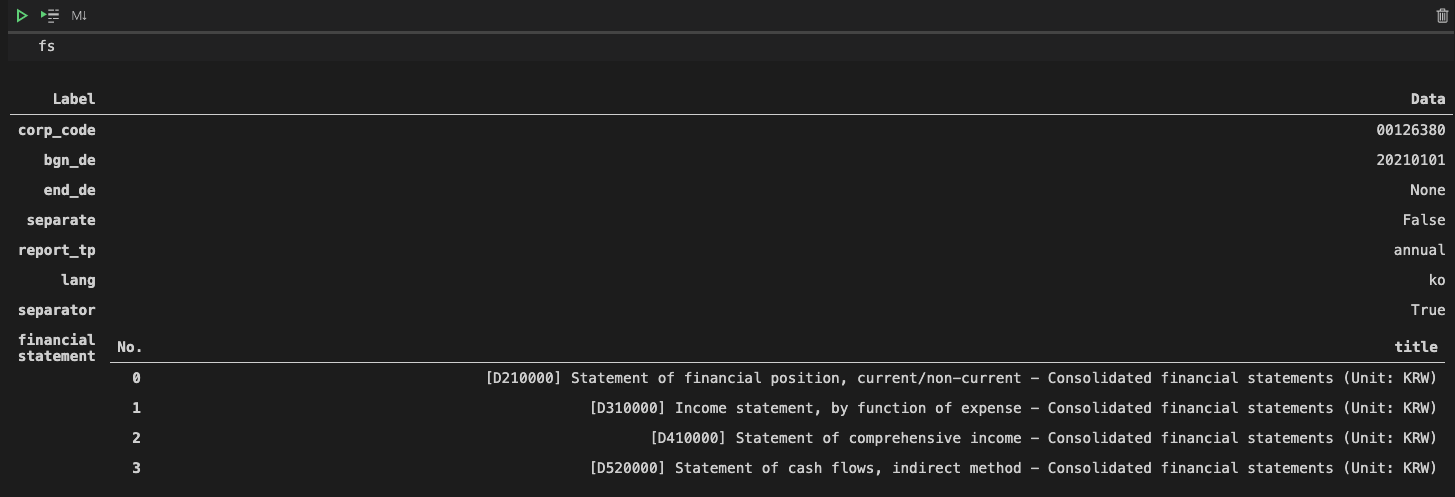
5) 연결/개별에 따라서 손익계산서를 데이터 프레임 형태로 가져오기
- 연결 재무제표라고 받아서, 손익계산서를 보면 연결/개별이 열을 번갈아가면서 함께 표현되어있음
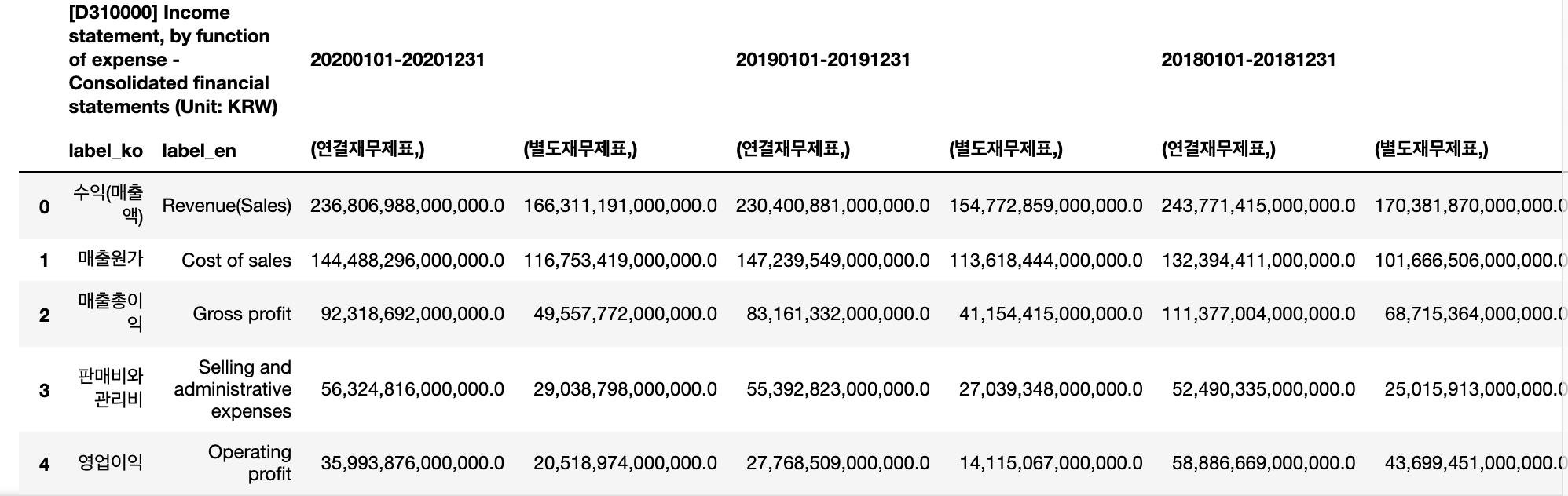
- 개별 재무제표는 당연히 연결에 대한 내용은 없음
- 참고로 손익계산서(is)와 포괄손익계산서(cis) 두 가지 개념이 있음 (is는 없고 cis만 있는 경우가 있음)
- 일반적으로 손익계산서는 매출(수익)에서 비용을 뺀 당기순이익까지를 나타내며, 기타포괄손익(미실현손익) 등을 포함한 손익계산서를 포괄손익계산서(국제회계기준, K-IFRS)라고 함
일단, 3, 4, 5번 컨셉을 지금까지 함수로 구현한 것은 아래와 같음 (추후 보완 예정)
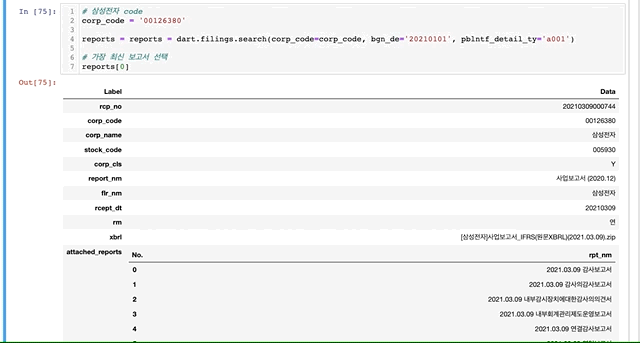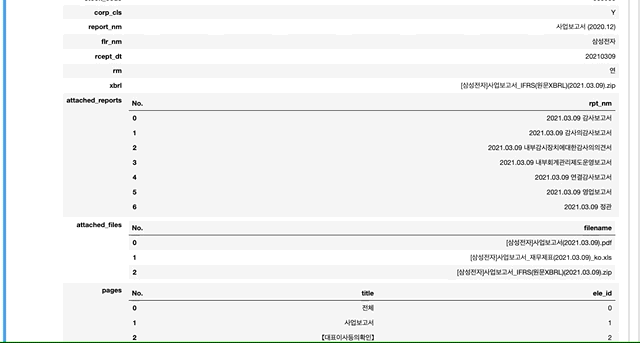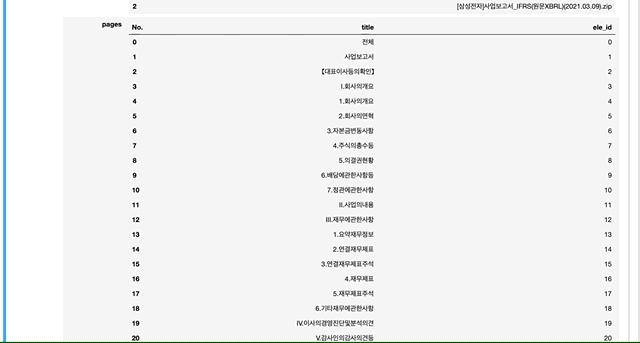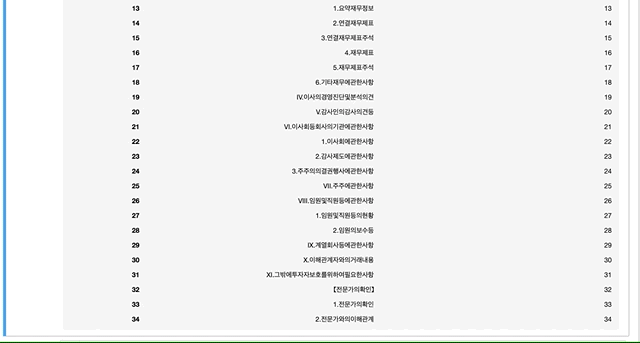
def search_annual_report(corp_code, bgn_de): data_company = corp_list.find_by_corp_code(corp_code) try: # 사업보고서 검색 reports = data_company.search_filings(bgn_de= bgn_de, pblntf_detail_ty='a001') # 첫번째 리포트 선택 report = reports[0] # 리포트의 xbrl 데이터 받아오기 xbrl = report.xbrl # 연결/개별 재무제표 여부 판단 (True/False) boolean = xbrl.exist_consolidated() if boolean == True: print('연결 재무제표') # 0에는 전체, 1에는 당기순이익부터 계산한 손익계산서가 들어있음 income_statement = xbrl.get_income_statement()[0] df = income_statement.to_DataFrame(show_concept=False, show_class=False) print(df.info) else: print('개별 재무제표') # 여기서는 True가 개별 손익계산서임에 주의 income_statement = xbrl.get_income_statement(separate=True)[0] df = income_statement.to_DataFrame(show_concept=False, show_class=False) print(df.info) return(boolean, df) except: print(data_company.corp_name + ':' + 'xbrl 없음(상품, 펀드)') return(False, False)
6) 데이터 프레임에서 원하는 정보 추출 (영업이익)
- 기업마다 양식이 통일 되지 않아서, 규칙을 잡기가 쉽지 않음 (해결해야하는 문제)
- 재무제표의 column index가 멀티 index로 되어 있음 (해결해야하는 문제)
7) 추출한 정보로 원하는 규칙을 적용하여 기업을 필터링
8) 나중에 더 나아가면 FinanceDataReader를 이용해 과거 주가를 토대로 백테스트를 할 수도 있음
이번 글은 스스로 정리하는 시간을 갖기 위해서 작성했으며, 빠른 시일 내로 해당 프로젝트를 완성하도록 하겠습니다.
관심있으신 분들은 또 들려주세요.
감사합니다.