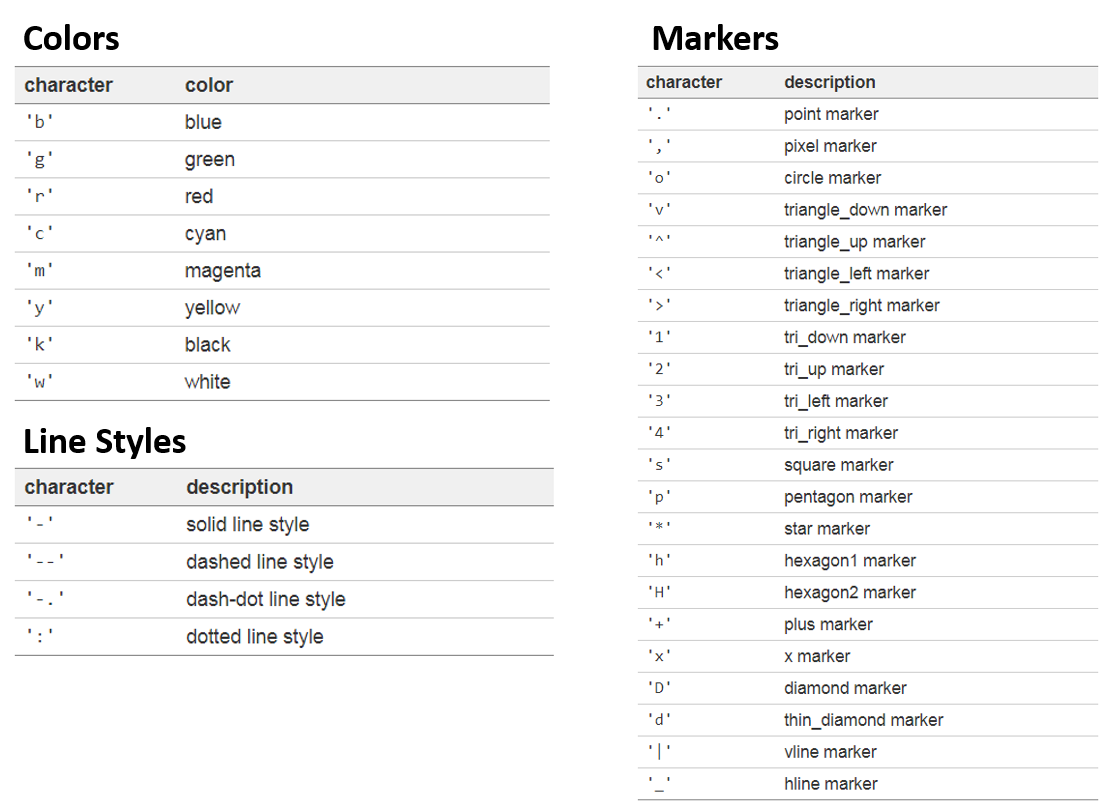
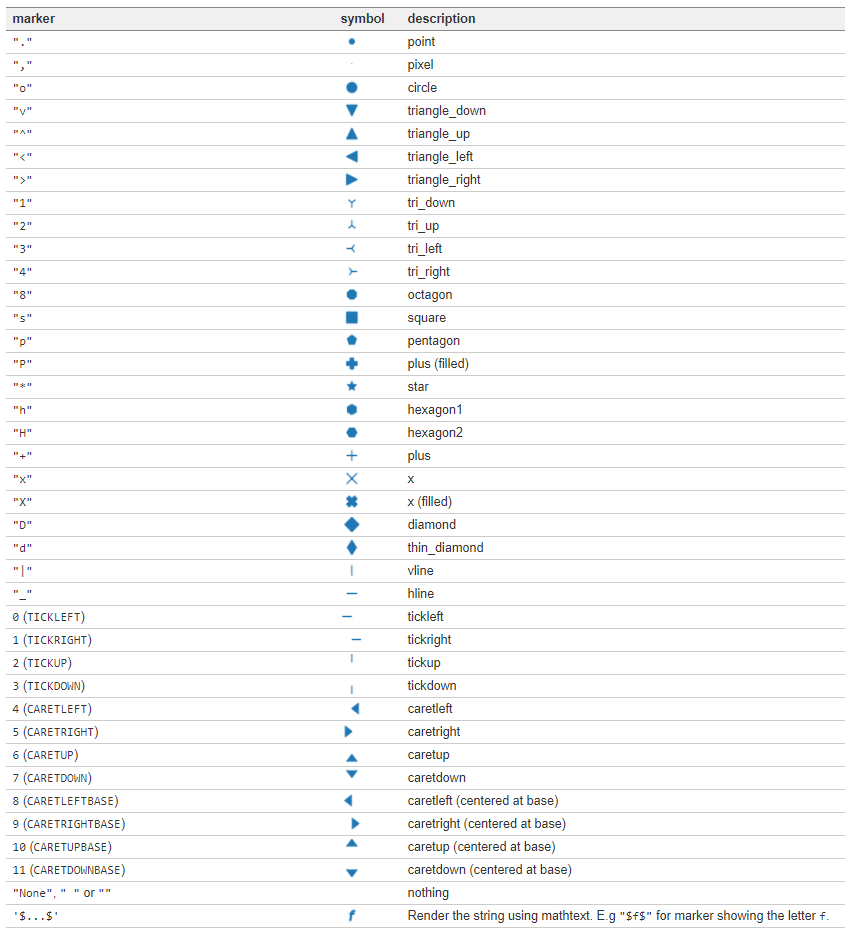
다시 본론으로 돌아와서 위에서 만든 pivot-table을 이용해 heatmap을 그려보겠습니다. 참고로 annot 파라미터를 True로 설정해주면 값을 칸 안에 표시해줍니다.
sns.heatmap(pivot, annot=True)
아래의 heatmap은 요일과 식사인원에 따른 팁의 평균을 직관적으로 보여줍니다.
전반적으로 식사인원이 많을 수록 많은 tip을 주고, 대략 인당 1달러를 팁으로 주는 듯하네요.
2) heatmap과 correlation matrix
이번에는 붓꽃 데이터를 이용해서 컬럼간의 상관관계를 heatmap으로 그려 보겠습니다.
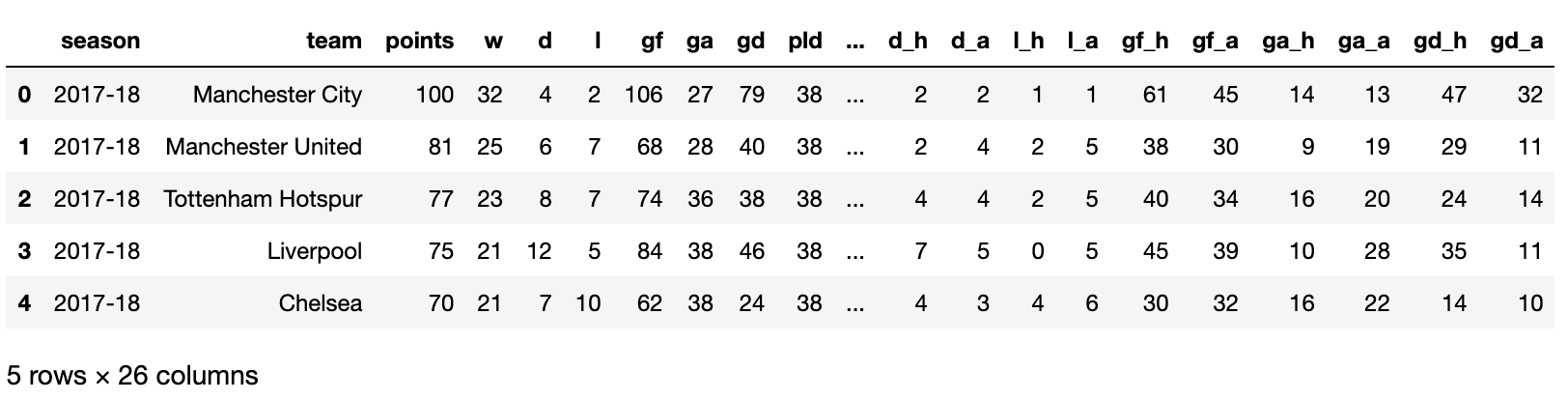
iris = sns.load_dataset("iris")
iris
corr( ) 함수를 이용해서 iris 데이터 셋의 컬럼들간의 관계를 2차원 행렬로 만들어 보겠습니다.
corr = iris.corr()
corr
같은 열끼리는 상관관계 정도가 1(동일)이며, -값의 경우는 반비례하는 상관관계를 가지는 것이라고 합니다.
마찬가지로 corr을 heatmap에 넣어서 그래프를 그려보겠습니다.
sns.heatmap(corr, annot=True)
아래의 데이터 셋의 의미를 참고해보았을 때, 다음과 같은 추론을 할 수 있습니다.
1) 꽃잎의 길이 길면 너비도 넓다.
2) 꽃잎의 길이와 꽃받침의 길이 또한 높은 상관관계를 가진다.
3) 꽃받침의 너비와 꽃받침의 길이는 거의 관계가 없다.
컬럼명
의미
sepal_length
꽃받침의 길이
sepal_width
꽃받침의 너비
petal_length
꽃잎의 길이
petal_width
꽃잎의 너비
참고로 상관 계수는 일반적으로,
값이 -1.0 ~ -0.7 이면, 강한 음적 상관관계 값이 -0.7 ~ -0.3 이면, 뚜렷한 음적 상관관계 값이 -0.3 ~ -0.1 이면, 약한 음적 상관관계 값이 -0.1 ~ +0.1 이면, 없다고 할 수 있는 상관관계 값이 +0.1 ~ +0.3 이면, 약한 양적 상관관계 값이 +0.3 ~ +0.7 이면, 뚜렷한 양적 상관관계 값이 +0.7 ~ +1.0 이면, 강한 양적 상관관계로 해석된다고 합니다.
아래의 그래프는 요일별로 흡연 여부에 따라 팁의 평균금액을 나타내 보았습니다. 흡연여부와 팁의 금액은 별로 상관 없어 보이네요.
여기서 위에 검은 막대가 무엇인지 궁금하실 텐데요. 이 막대는 오차를 나타내는 막대입니다.
ci 파라미터는 3가지 옵션(숫자 / 'sd' / None)을 가질 수 있으며, 숫자는 신뢰구간(%), 'sd'는 표준편차, None은 표현하지 않음을 의미합니다. 자세한 설명을 위해서는 통계 지식이 필요하므로 추후에 설명하기로 하고, None을 넣어서 검은색 막대를 없애보겠습니다.
이번 코드에서 주의 깊게 보실부분은 ci 설정과 x와 y의 데이터를 바꾸어줌으로써 수평막대 그래프로 바뀐 것입니다.
kdeplot은 커널 밀도 추정(kernal density estimation) 그래프로 histplot이 count(절대량)을 표현한다면 kdeplot은 비율(상대량)을 시각화 합니다. histplot과 마찬가지로 하나 혹은 두 개의 변수에 대한 분포를 그릴 수 있습니다.
대략적으로 어떤 느낌인지 감이 오시나요? rugplot은 다른 그래프를 보완해주는 그래프라고 생각하시면 되겠습니다.
4. ecdfplot
ecdfplot은 분포를 누적화해서 보여줍니다. 아직 잘 모르지만 그리 많이 쓰일 것 같아 보이진 않네요.
sns.ecdfplot(data=iris, x='sepal_length')
5. distplot
지난 시간에 배웠던 relplot과 같이 앞서 배운 4가지 plot들을 모두 그려줄 수 있는 함수입니다.
kind 파라미터를 histplot, kdeplot, ecdfplot으로 설정해줌으로써 3가지 plot을 그릴 수 있고, rug 옵션을 True/False로 설정하여 나타낼 수도 있고 나타내지 않을 수도 있습니다. 참고로 kind의 기본값은 hist로 아무 설정이 없을 때는 histplot을 그려줍니다.
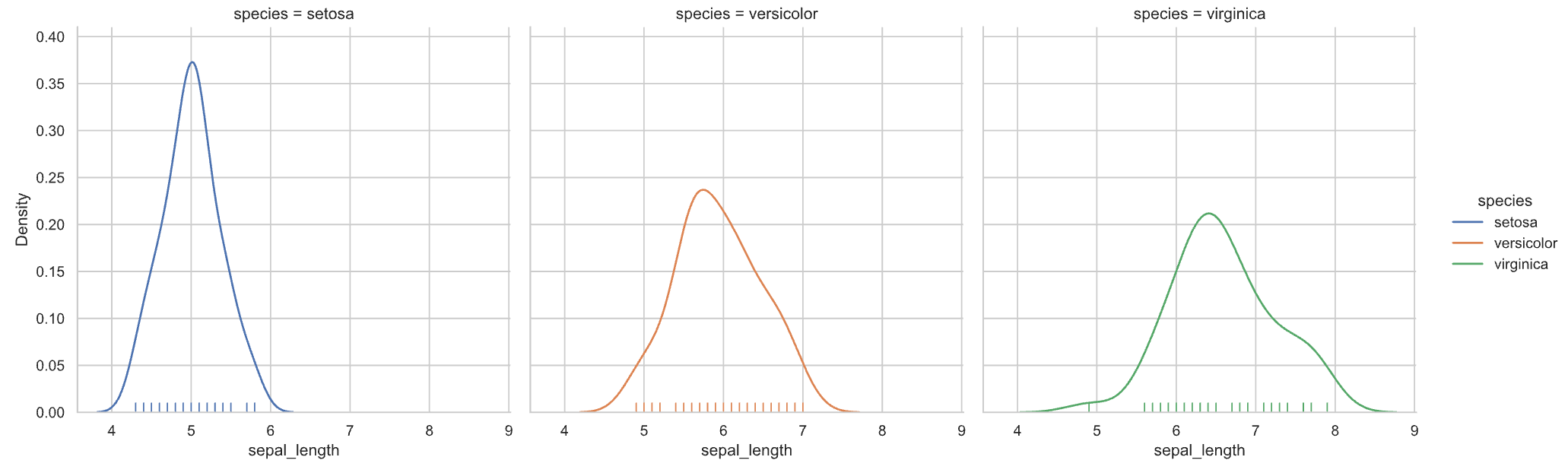
또한 중요한 특징으로, row와 col 파라미터를 이용해서 subplot을 여러개 함께 나타낼 수 있습니다.
모든 그래프를 한 번에 공부하기엔 너무 양이 많으므로, 이번 시간에는 Relational plots과 Distribution plots에 대해서만 다루어보겠습니다. 데이터 셋은 지난 시간에 배웠던 데이터 셋 중, tips에 대한 데이터 셋을 이용할 예정입니다.
그래프를 그려보기 위해서 관련 라이브러리와 데이터 셋을 불러오겠습니다. 이번 시간에도 개발환경은 역시 Jupyter Notebook입니다.
# 관련 라이브러리 불러오기
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
# 데이터 셋 불러오기
tips = sns.load_dataset("tips")
tips
Relational plots
가장 먼저 배워볼 그래프는 관계형 그래프(Relational plots) 입니다. 우리가 흔히 아는 Line 그래프도 x와 y의 관계를 그려주는 관계형 그래프의 한 종류입니다.
Relational plots에는 크게 라인 그래프(lineplot)와 산점도 그래프(scatterplot)으로 나뉘며, 이 둘을 합친 개념인 relplot이 있습니다.
나중에 자세히 설명드리겠지만 relplot의 파라미터로 kind="scatter" 혹은 "line"을 입력해주시면 두 그래프를 relplot을 이용하여 동일하게 사용가능합니다. 즉, replot = lineplot + scatterplot인 것이죠!
1. scatterplot
먼저 sctterplot을 알아보겠습니다. scatterplot을 그려주기 위해서는 3가지 파라미터가 꼭 필요합니다.
막대별로 다른 색상을 넣거나, 막대의 폭, 테두리 등의 스타일 설정도 가능합니다. 여기서는 다양한 그래프를 다룰 예정이므로 자세한 내용은 글 마지막의 참고 자료를 참고해주세요.
참고로 label, legend, title 등은 지난 시간에 배운 내용이 똑같이 적용 가능하답니다.
수평 막대 그래프
: plt.barh(y, x)
수평 막대 그래프는 위에서 배운 막대 그래프를 90도 회전시켜서 눞혀 놓았다고 생각하시면 됩니다.
인자로 y축 데이터를 먼저 받는다는 점만 주의하시면 되겠습니다. 그 외의 기타 설정들은 위에서 설명드린 내용과 동일합니다.
# data 생성
data_y = np.arange(11, 21)
data_x = np.arange(1, 11)
# 수평 막대 그래프 그래프
plt.barh(data_y, data_x)
# 그래프 출력
plt.show()
파이 차트
: plt.pie( )
파이 차트는 여러가지 항목의 비율(%)를 효과적으로 나타낼 수 있는 그래프입니다. 참고로 autopct라는 파라미터를 설정해주지 않으면 데이터가 그래프에 표시되지 않는답니다.
# ratio (모두 합쳐서 100이 되지 않으면 자동으로 전체의 합에서 각각의 비율을 나타냄)
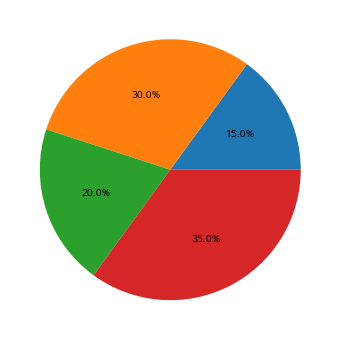
data = [15, 30, 20, 35]
plt.pie(data, autopct='%.1f%%')
plt.show()
아주 순수 그자체의 pie 차트 -> 못써먹음
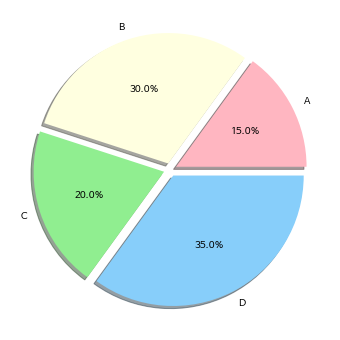
여기까지만 알려드리면 파이차트는 정말 쓸모가 없을 듯 하여, 옵션들을 설정해서 쓸만하게 만들어보겠습니다.
많은 옵션들이 있지만 labels, explodes, colors, shadow 정도면 충분할 듯 하여, 이것들만 다루었습니다.
ratio = [15, 30, 20, 35]
# 각 영역의 범례
labels = ['A', 'B', 'C', 'D']
# 각 영역이 중심으로부터 떨어진 거리
explode = [0.05, 0.05, 0.05, 0.05]
# 각 영역의 색상
colors = ['lightpink', 'lightyellow', 'lightgreen', 'lightskyblue']
plt.pie(ratio, autopct='%.1f%%', labels=labels, explode=explode, colors=colors, shadow=True)
plt.show()
산점도 그래프
: plt.scatter( )
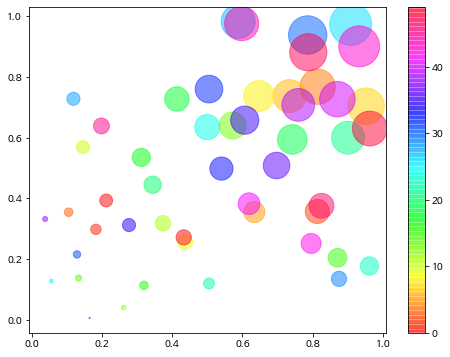
산점도 그래프는 데이터들이 얼마나 분포해 있는지, 그 값의 크기는 어느정도인지를 한 눈에 볼 수 있도록 표현한 그래프입니다.
# 0~1 사이의 실수를 무작위으로 50개 생성 (x, y 좌표로 활용)
x = np.random.rand(50)
y = np.random.rand(50)
# 각 점들의 색상 부여를 위한 Array 생성 (데이터와 동일한 50개 필요)
colors = np.arange(50)
# 각 점들의 면적을 부여해서 다양한 점의 면적 표현
area = x * y * 2000
# 0~1 사이의 투명도를 설정하여 점이 겹쳤을 때를 더 예쁘게 표현 가능
alpha= 0.5
# 산점도 그래프 그리기 (여기서 cmap은 matplotlib에 정의된 컬러 조합임)
plt.scatter(x, y, s=area, c=colors, alpha=alpha, cmap='hsv')
# 산점도 그래프 우측에 컬러가 무엇을 뜻하는지 컬러바 표현
plt.colorbar()
# 그래프 출력
plt.show()
c(color)나 s(area), alpha, colorbar( )와 같은 설정을 해주지 않으면 아래와 같이 허접한(?) 산점도 그래프를 얻을 수 있습니다.
위에서 같이 예쁜 컬러를 얻기 위해서는 cmap 설정을 할 수 있으며, 그 양이 방대해서 참고 자료로 대체하도록 하겠습니다. 원하는 컬러맵을 골라서 사용하시면 되겠습니다.