반응형
안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석, 머신러닝 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

오늘은 코딩유치원 학생분께서 요청하신 프로젝트를 완료해서 공유드리려고 해요.
이 프로젝트의 목적은 제목과 같이 특정 스마트스토어의 최신제품을 실시간 크롤링하고 제품명, 가격정보, 제품링크를 텔레그램으로 전송하는 것입니다.
아래의 프로젝트와 비슷했지만, 링크와 제품명, 가격을 묶어주고 전송해줘야해서 dictionary 문법을 사용해보았습니다.
2021.04.05 - [파이썬 패키지/텔레그램(Telegram)] - [Python/Telegram] 원하는 주제의 네이버 뉴스 텔레그램으로 5분마다 전송 받기
코드는 마음 껏 사용하셔도 되며, 잘 이해가 가지 않으시면 댓글 달아주세요~!
<전체 코드>
#step1.라이브러리 불러오기
import requests
from bs4 import BeautifulSoup as bs
import telegram
import schedule
import time
#step2.새로운 네이버 뉴스 기사 링크를 받아오는 함수
def get_new_products(old_products={}):
product_links = []
product_prices = []
product_names = []
# step3.for문을 이용해서 원하는 페이지에 접근, 정보 추출 후 리스트에 담기
for page_num in range(3): #여기서는 3번째 페이지까지만 크롤링 하도록 설정
# range를 이용하면 0부터 인덱스가 시작되므로 page_num에 1을 더해준 url을 이용
url = f'https://smartstore.naver.com/compuzone/category/ALL?st=RECENT&free=false&dt=IMAGE&page={page_num+1}&size=40'
# html 정보 받아와서 파싱
response = requests.get(url)
soup = bs(response.text , 'html.parser')
# css selector로 페이지 내의 원하는 정보 가져오기
# html_product_links = soup.select('a._3BkKgDHq3l.N=a:lst.product.linkAnchor') --> 잘 작동하지 않음
html_name = soup.select('strong.QNNliuiAk3')
html_price = soup.select('span.nIAdxeTzhx')
html_product_links = soup.select('li.-qHwcFXhj0 > a')
# 제품 이름 추출해서 리스트에 저장
for i in html_name:
product_names.append(i.get_text())
# 제품 가격 추출해서 리스트에 저장
for i in html_price:
product_prices.append(i.get_text())
# 제품 링크 추출해서 리스트에 저장
for i in html_product_links:
product_links.append('https://smartstore.naver.com' + i.attrs['href'])
# 제품 링크를 key, 제품이름과 가격을 value로 dictonary 만듦
dict_product = dict(zip(product_links, zip(product_names, product_prices)))
# 기존의 링크와 신규 링크를 비교해서 새로운 링크만 저장
new_products = {key:info for key, info in dict_product.items() if key not in old_products}
return new_products
#step3.새로운 네이버 뉴스 기사가 있을 때 텔레그램으로 전송하는 함수
def send_products():
# 함수 내에서 처리된 리스트를 함수 외부에서 참조하기 위함
global old_products
# 위에서 정의했던 함수 실행
new_products = get_new_products(old_products)
# 새로운 메시지가 있으면 링크 전송
if new_products:
for key in new_products:
bot.sendMessage(chat_id=chat_id,
text= new_products[key][0] +
'\n\n' + '가격:' + new_products[key][1] + '원' +
'\n\n' + key)
else:
# bot.sendMessage(chat_id=chat_id, text="새로운 제품이 없습니다.") --> 잘 실행되는지 확인하고 싶으면 pass 대신 활성화
pass
# 기존 제품 정보를 계속 축적하기 위함
old_products.update(new_products)
# 실제 프로그램 구동
if __name__ == '__main__':
#토큰을 변수에 저장
bot_token ='자신의 텔레그램 봇 토큰 번호'
bot = telegram.Bot(token = bot_token)
# 자신의 봇의 chat_id
chat_id = '1516137537'
#위에서 얻은 chat id로 bot이 메세지를 보냄.
bot.sendMessage(chat_id = chat_id, text="컴퓨존의 새제품 실시간 크롤링이 시작 되었습니다")
# #step5.기존에 보냈던 링크를 담아둘 리스트 만들기
old_products = {}
# 가장 처음 실행 시, 한 번만 old_products에 제품 링크들 저장
old_products = get_new_products(old_products)
# 주기적 실행과 관련된 코드 (hours는 시, minutes는 분, seconds는 초)
job = schedule.every(10).seconds.do(send_products)
while True:
schedule.run_pending()
time.sleep(1)
<실행 결과>
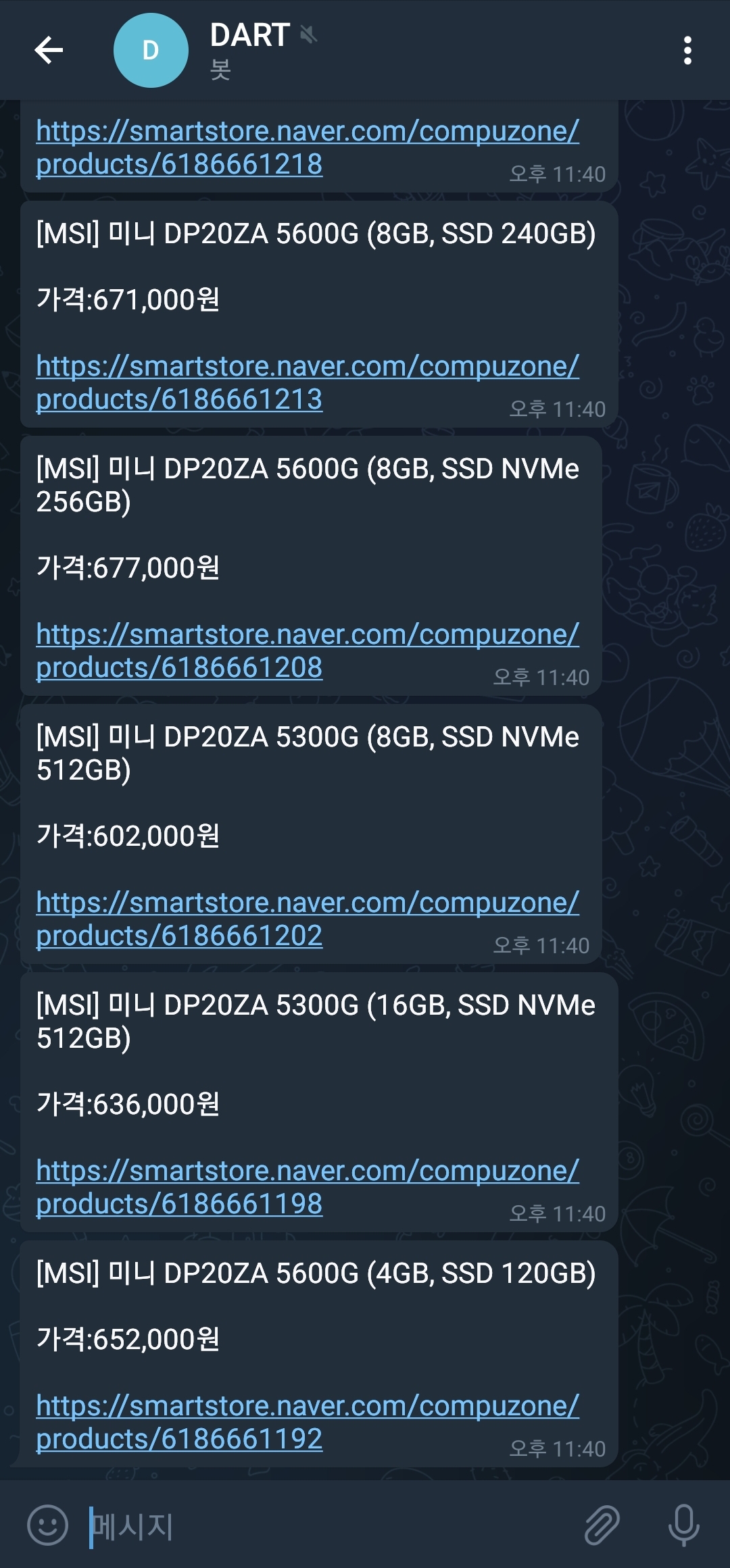
반응형
'파이썬 프로젝트' 카테고리의 다른 글
| [파이썬 프로젝트] 파이썬으로 홈쇼핑 편성표 크롤링하기 (날짜, 상품, 가격, 시간대) (4) | 2022.09.28 |
|---|---|
| [파이썬 프로젝트] 네이버 뉴스 댓글 크롤링 (2) | 2021.11.29 |
| 일론 머스크 트위터 실시간 크롤링을 통한 도지코인 매매 수익률 검증 (feat. How much is that Doge in the window?) (0) | 2021.05.20 |
| 일론 머스크 트위터 실시간 크롤링을 통한 비트코인 매매 수익률 검증 (feat. Tesla has Diamond Hands) (0) | 2021.05.20 |
| [파이썬 프로젝트] 파이썬 코드 실시간 실행을 위한 나만의 서버 만들기(feat. 네이버 클라우드 플랫폼) (4) | 2021.05.15 |