안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
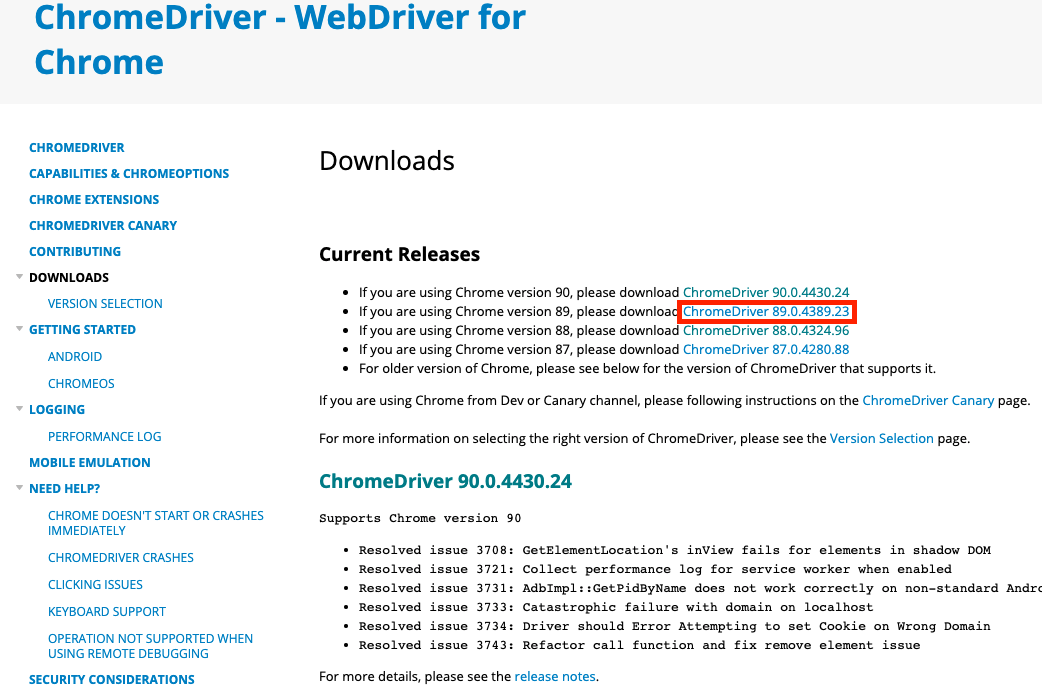
2022.03.11 - [파이썬 패키지/라이브러리&패키지 소개] - 파이썬 주요 라이브러리 정리

1. 요상한 클래스명이란?
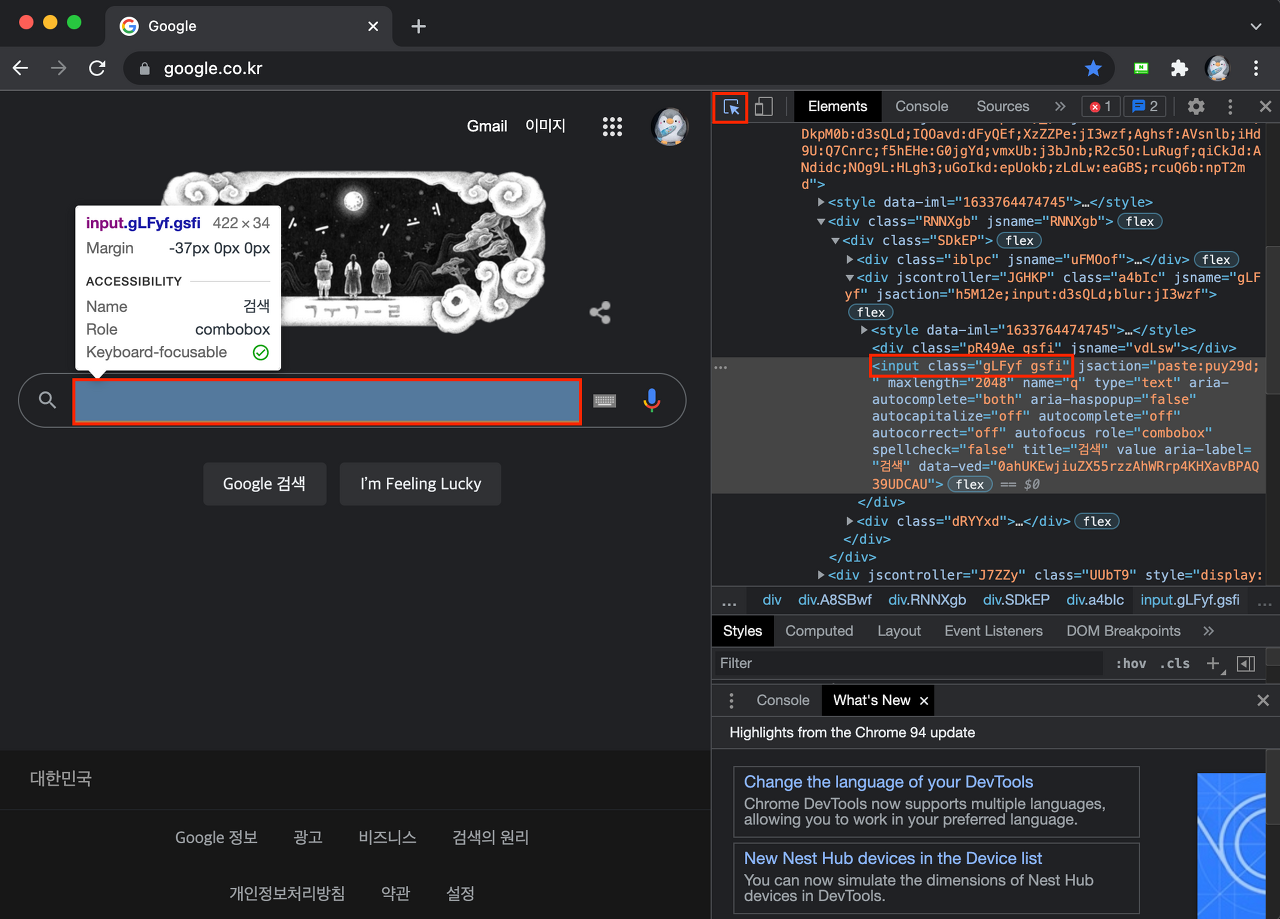
최근 들어 아래와 같은 길고 빈칸이 많은 클래스 명을 사용해서 웹사이트를 구현하는 곳이 많아졌습니다. 저는 Web 개발자가 아니다 보니 도대체 어쩌다가 이런 요상한 클래스명을 사용하는지 궁금해져서 ChatGPT에게 물어봤습니다.

답변 받은 내용을 요약하자면 다음과 같습니다.
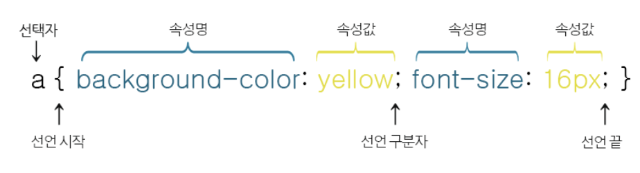
1. 이러한 CSS 선택자 방식을 "유틸리티 클래스" 또는 "유틸리티 퍼스트 CSS"라고 합니다. 이는 주로 Tailwind CSS 프레임워크에서 사용되는 접근 방식입니다. (참고로 CSS란 웹페이지를 꾸며주는 문법을 뜻합니다.)
2. 이러한 방식을 웹사이트 개발자가 사용하는 이유는 클래스 이름이 직관적이며 HTML 요소에 직접 스타일을 적용할 수 있어 빠른 개발이 가능하기 때문이라고 합니다. 또한 반응형 디자인과 테마 변경 등에 유연하게 대응할 수 있다고 합니다. 한마디로 웹사이트 개발자가 웹 프로그래밍 할 때 편한 방식이라 이해하시면 될 것 같습니다
3. 이 방식은 CSS 작성 시간을 줄이고 일관된 디자인을 유지하는 데 도움이 되지만, HTML이 다소 복잡해 보일 수 있다는 단점도 있습니다.
2. 유틸리티 퍼스트 CSS가 웹크롤링 할 때 까다로운 이유
안타깝게도 "유틸리스 클래스" 방식의 웹 사이트는 제가 지금까지 블로그나 책을 통해서 알려드린 방법으로 웹크롤링하기가 매우 까다롭습니다.
이유는 많지만 딱하나만 꼽아도 충분할 것 같습니다. 그 이유는 바로 띄어쓰기가 많다는 것입니다.
아래와 같이 class name이나 id에 가끔 띄어쓰기가 존재하는 경우에는 빈칸 대신 . (dot)을 입력해 주어야 합니다. 모를 때는 정말 고생하는 내용이고 알더라도 위에서 보신 클래스명과 같은 경우는 모든 빈칸들을 .으로 변경해줘야하기 때문에 매우 번거롭습니다.

driver.find_element(By.CLASS_NAME, "thumb.api_get")
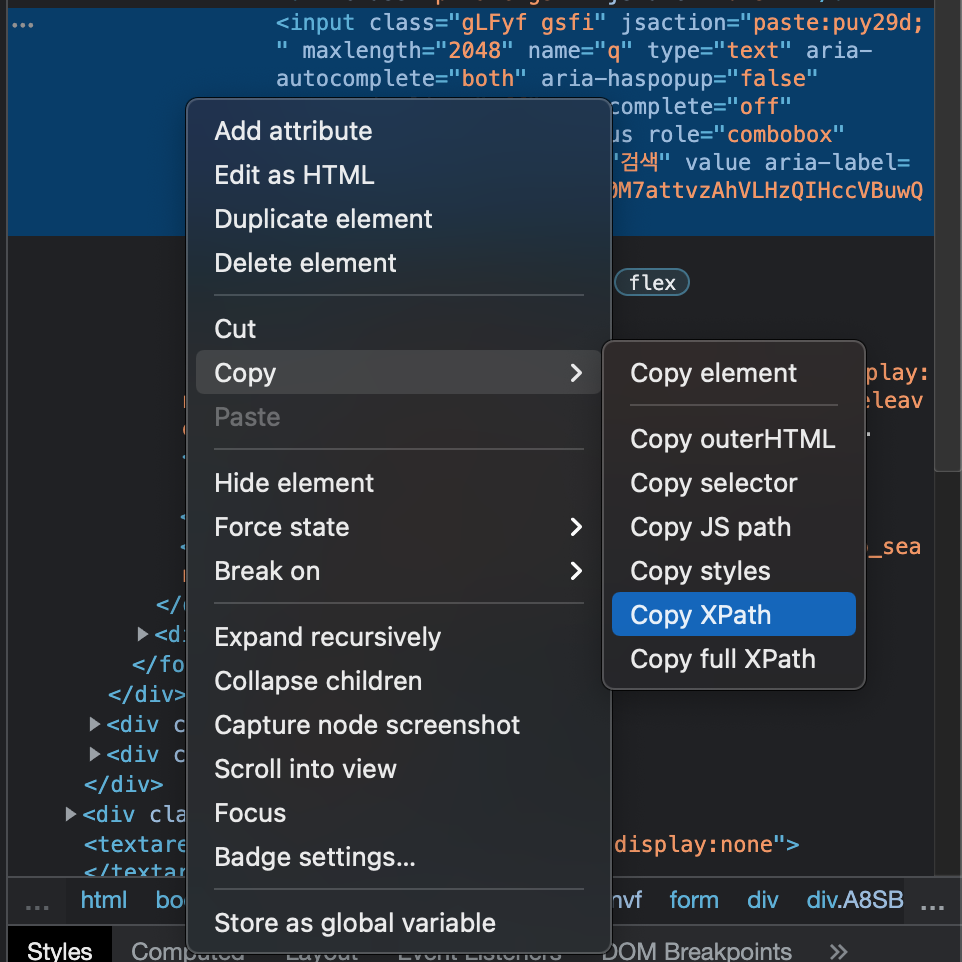
3. XPATH를 이용한 CLASS_NAME 인덱싱
그럼 기존 방식과 새로 알려드릴 방식을 비교하며 설명드려 보겠습니다. 자세히 보시면 " "로 쌓여진 클래스명에는 7개의 띄어쓰기가 존재합니다. 기존 방식으로는 이 띄어쓰기를 하나씩 찾아서 .으로 바꿔줘야 하죠.
[크롤링할 HTML 요소]
<a class="btn_pgnext inline-block h-[38px] w-[37px] bg-[url(https://common.jobplanet.co.kr/images/common/global_spt.png)] bg-[-96px_0] bg-no-repeat hover:bg-[-96px_-48px]" href=""><span class="sr-only">Next</span></a>
[기존 방식]
driver.find_element(By.CLASS_NAME, "btn_pgnext.inline-block.h-[38px].w-[37px].bg-[url(https://common.jobplanet.co.kr/images/common/global_spt.png)].bg-[-96px_0].bg-no-repeat.hover:bg-[-96px_-48px]"
[BY.XPATH 방식]
driver.find_element(By.XPATH, "//*[@class='btn_pgnext inline-block h-[38px] w-[37px] bg-[url(https://common.jobplanet.co.kr/images/common/global_spt.png)] bg-[-96px_0] bg-no-repeat hover:bg-[-96px_-48px]']")
하지만 driver.find_element(By.XPATH, "//*[@class='btn_pgnext inline-block h-[38px] w-[37px] bg-[url(https://common.jobplanet.co.kr/images/common/global_spt.png)] bg-[-96px_0] bg-no-repeat hover:bg-[-96px_-48px]']") 와 같이 붉은색으로 표시된 부분에 클래스명을 그대로 붙여넣어 주기만 하면 띄어쓰기에 대한 고민 없이 웹 크롤링이 가능합니다.
이외에도 XPATH를 활용해서 HTML 요소를 찾는 방법들을 최근 알게되었는데 이 부분은 다음 시간에 더 자세히 다루어보도록 하겠습니다.
오늘 준비한 내용은 여기까지입니다. 오늘도 코딩유치원을 찾아주셔서 감사합니다.
'파이썬 패키지 > 웹 크롤링' 카테고리의 다른 글
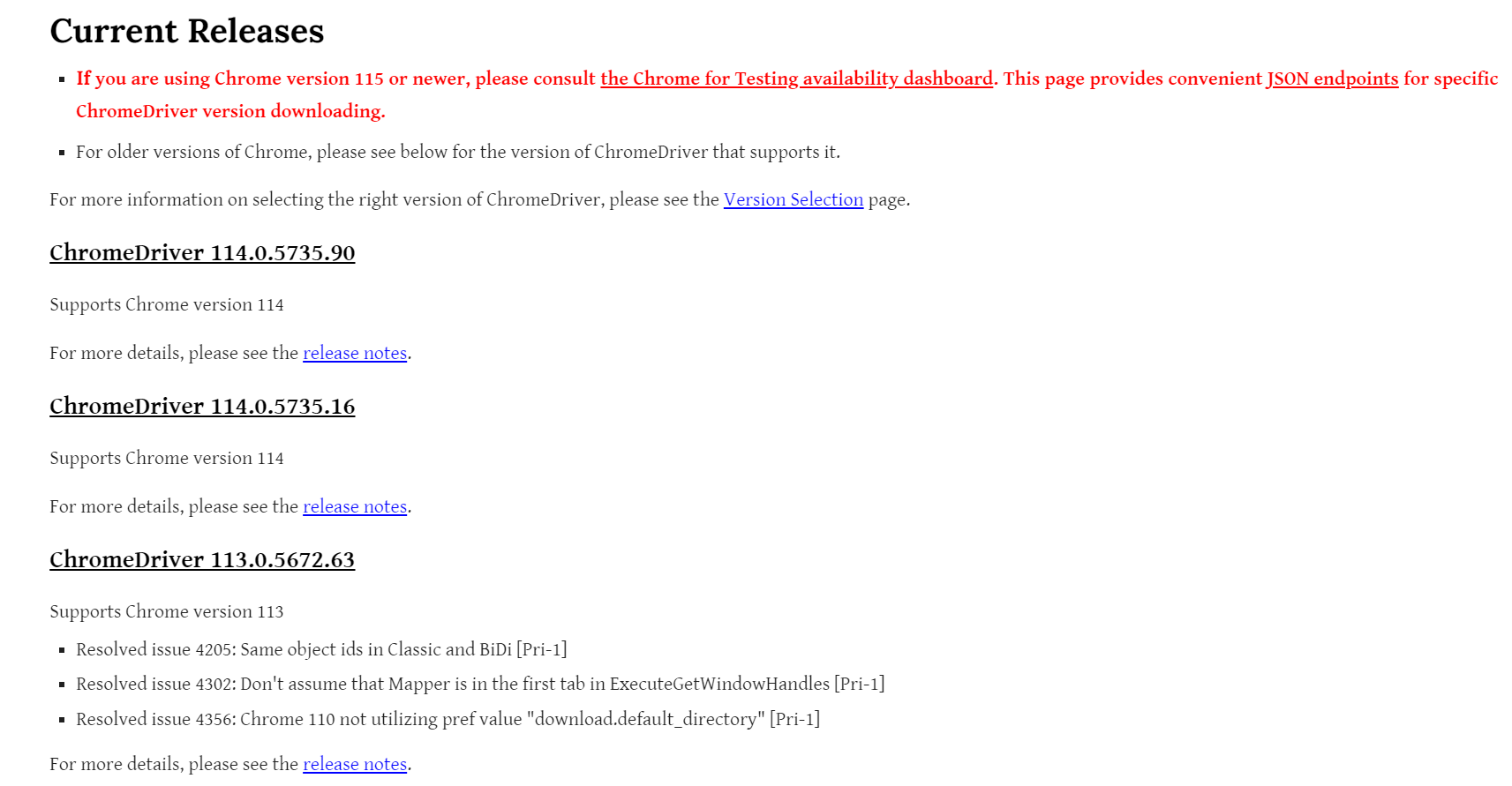
| [python/selenium] Chromdriver 115 버전 이후의 에러의 발생원인과 해결방법 (2) | 2023.09.16 |
|---|---|
| [python/selenium] 파이썬으로 인스타그램 크롤링하기 1편. 로그인하기 (3) | 2022.09.23 |
| [Python/웹 크롤링] 정적 웹크롤링 방식으로 여러 페이지 정보 가져오기 (14) | 2022.01.10 |
| [Python/Selenium] Selenium으로 click( ) 하다가 안될 때는 iframe을 전환해야 한다(ft. NoSuchElementException) (1) | 2021.12.02 |
| [Python/Selenium] 파이썬 동적 웹크롤링_selenium으로 화면 조작하기(ft.버튼 클릭, 키 입력, 스크롤 내리기) (2) | 2021.10.21 |