안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.

오늘은 파이썬을 이용해 zip 파일을 만드는 방법에 대해 알아보겠습니다. 사무자동화를 할 때에 압축된 폴더를 다운로드 받거나, 압축해서 업로드 해야할 때 사용할 수 있습니다.
관련 패키지 불러오기
zipfile은 파이썬 표준 라이브로리로 따로 설치할 필요는 없고 import로 불러와주시면 됩니다.
import zipfile
import os
<파이썬 표준 라이브러리_zipfile 공식 문서>
https://docs.python.org/ko/3/library/zipfile.html
zipfile — ZIP 아카이브 작업 — Python 3.9.6 문서
zipfile — ZIP 아카이브 작업 소스 코드: Lib/zipfile.py ZIP 파일 형식은 흔히 쓰이는 아카이브와 압축 표준입니다. 이 모듈은 ZIP 파일을 만들고, 읽고, 쓰고, 추가하고, 나열하는 도구를 제공합니다. 이
docs.python.org
압축하기
바로 압축하는 방법에 대해서 알아보겠습니다. 원리는 간단합니다.
압축하고자 하는 zip 파일 생성 - zip 파일에 넣고 싶은 파일 write - zip 파일 닫기
이 3단계를 하나의 파일을 압축하는 경우와 여러개의 파일을 압축하는 경우 2가지로 나눠서 설명드려 보겠습니다.
하나의 파일 압축하기
1단계. 압축하고자 하는 zip 파일 생성 (꼭 os.chdir로 현재 경로를 바꾸어 줄 것)
먼저 os.chdir( )로 현재 작업할 경로를 다시 설정해줄 필요가 있습니다. 그러지 않고 절대 경로로 할 시, 의도와 다르게 가장 상위 디렉토리(폴더)부터 모든 디렉토리가 압축됩니다.
또한 zip 파일 생성을 위해 폴더를 따로 만들어 줄 필요가 없습니다. 곧 바로 zip 파일이 생성되는 것이니깐요.
os.chdir('/Users/username/Desktop/zipfile 패키지 테스트 폴더')
my_zip = zipfile.ZipFile('코딩유치원.zip', 'w')
<실행 결과> 코딩유치원.zip 생성됨

현재의 상태(zip 파일 close 안 해줌)에서는 아래와 같이 zip 파일을 열 수가 없다는 점 참고바랍니다.

2단계. 생성한 zip 파일에 넣고자 하는 파일 입력하기
아까 설정해준 현재 작업 경로에 test1.txt를 생성해두고 그것을 write 해줍니다.
참고로 현재 작업 폴더가 아닌 곳의 test1 파일을 write( '절대경로')로 입력할 시, 이상하게 작동하니 주의하세요.
# 현재 작업 경로에 test1.txt 파일이 있어야 함
my_zip.write('test1.txt')
<실행 결과> 코딩유치원.zip 안에 test1.txt 들어감
현재 상태에서도 zip 파일을 더블클릭해서 열어보려 해도 아래와 같은 경고창이 뜨면서 확인할 수가 없습니다.

3단계. zip 파일 닫기
zip 파일 안에 원하는 파일을 모두 넣으셨다면 close( ) 메소드를 통해 zip를 닫아주어야합니다.
my_zip.close()
<실행 결과> 코딩유치원.zip을 더블 클릭하여 압축해제 시
의도와 다르게 가장 상위 디렉토리(폴더)부터 모든 디렉토리가 압축된 것을 확인 할 수 있습니다. 다른 방법이 필요하겠습니다.
<주의!>
만약 경로를 chdir( )로 바꾸어 주지 않고 절대 경로를 사용하여 압축할 시 아래와 같이 의도치 않은 압축 파일이 생성됩니다.
my_zip = zipfile.ZipFile('/Users/username/Desktop/zipfile 패키지 테스트 폴더/코딩유치원.zip', 'w')
my_zip.write('/Users/sangwoo/Desktop/zipfile 패키지 테스트 폴더/코딩유치원/test1.txt')
my_zip.close()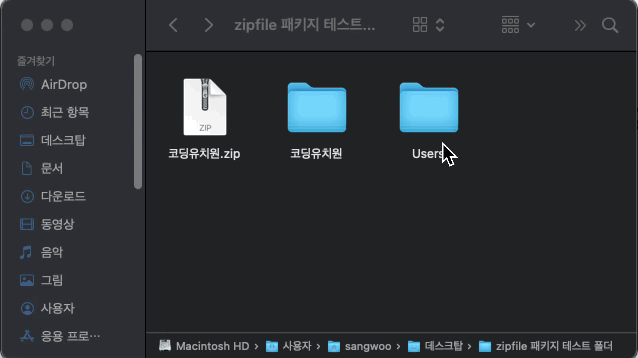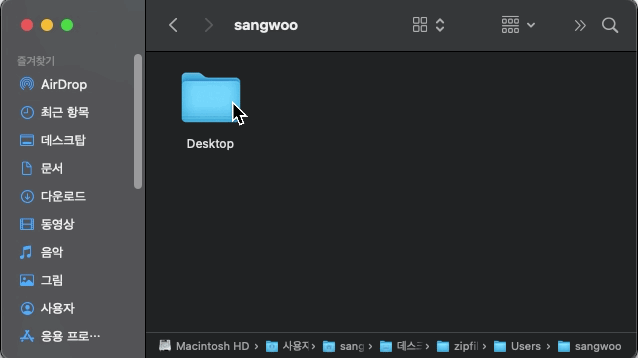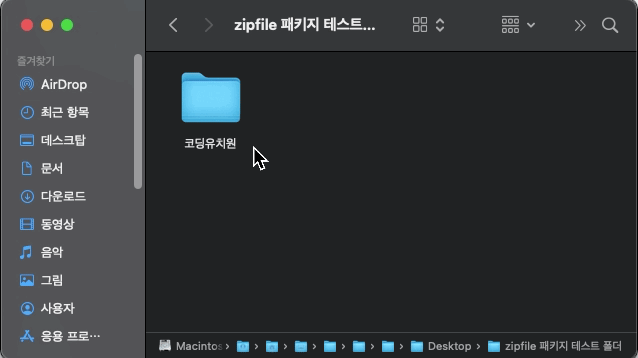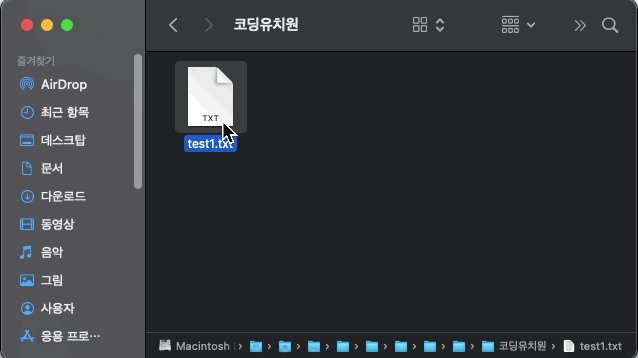
여러개의 파일 압축하기
여러개의 파일을 한꺼번에 압축하려면 with 문과 for문을 함께 사용해 주시면 됩니다.
아래의 코드를 보시고 직접 한 번 해보시기 바랍니다. 그 외 개념은 위에서 했던 것과 같으므로 자세한 설명은 생략하도록 하겠습니다.
file_list = ['코딩유치원.txt', '투손플레이스.txt', '고양이미로.xlsx']
with zipfile.ZipFile("코딩은 코딩유치원이지ㅎㅎ.zip", 'w') as my_zip:
for i in file_list:
my_zip.write(i)
my_zip.close()
<실행 결과>

압축해제
압축을 해제 하는 방법은 크게 2가지가 있습니다. 여러 파일 중 1개만 골라서 압축해제하는 방법과 전체를 다 압축해제하는 방법입니다.
개별파일 압축해제
ZipFile.extract(member, path=None, pwd=None)
path에는 추출할 zip 폴더의 경로를 넣어줄 수 있으며, 넣어주지 않으면 현재 작업 폴더로 지정한 파일을 추출합니다. member는 파일명.확장자명이며, pwd는 암호화된 파일에 사용되는 비밀번호입니다.
zipfile.ZipFile('코딩은 코딩유치원이지ㅎㅎ.zip').extract('코딩유치원.txt')
<실행 결과>

모든파일 압축해제
ZipFile.extractall(path=None, members=None, pwd=None)
path에는 추출할 zip 폴더의 경로를 넣어줄 수 있으며, 넣어주지 않으면 현재 작업 폴더로 지정한 파일을 추출합니다. members에는 리스트 형식의 '파일명'을 넣어주시면 선택적으로 여러개의 파일을 압축해제 가능하며, pwd는 암호화된 파일에 사용되는 비밀번호입니다.
# 전체를 압축해제 하고 싶을 때
zipfile.ZipFile('코딩은 코딩유치원이지ㅎㅎ.zip').extractall()
# 전체가 아닌 몇 개만 압축해제 하고 싶을 때
zipfile.ZipFile('코딩은 코딩유치원이지ㅎㅎ.zip').extractall(members = ['투손플레이스.txt','고양이미로.xlsx'])
오늘은 zipfile 패키지를 이용해 zip 파일의 압축/압축 해제 하는 방법에 대해서 알아보았습니다.
긴 내용 읽으며 공부하신 여러분! 고생 많으셨습니다!!
'파이썬 패키지 > 폴더, 파일관리' 카테고리의 다른 글
| [python/shutil] 파일과 폴더를 이동하거나 복사하고 싶을 때 사용하는 shutil 모듈 정리 (0) | 2021.12.20 |
|---|---|
| [Python / os모듈] 디렉토리(폴더)와 경로 정보 활용하기 (0) | 2021.06.07 |