녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석, 머신러닝 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

[웹 크롤링 기초]
2021.03.22 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 파이썬 웹 크롤링 기초 of 기초
2021.03.23 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 크롬드라이버 크롬 버전에 맞춰서 설치하는법
2021.03.24 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 파이썬 웹 크롤링 관련 패키지 3종 총정리
2021.03.27 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 파이썬 웹 크롤링을 위한 속성 HTML, CSS 요약 정리
2021.03.28 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 동적/정적 페이지 차이와 그에 따른 크롤링 방법 간단정리
[정적 웹크롤링]
2021.04.02 - [파이썬 패키지/웹 크롤링] - [Python/Requests/Beautifulsoup] 네이버 뉴스 기사 제목 크롤링을 통한 정적 수집 기초 정리
[동적 웹크롤링]
2021.04.03 - [분류 전체보기] - [코딩유치원] 네이버 뉴스 기사 제목 크롤링을 통한 동적 수집 기초 정리(selenium, beautifulsoup)
2021.06.21 - [파이썬 패키지/웹 크롤링] - [Python/Selenium] 파이썬 동적 웹크롤링 텍스트, 하이퍼링크, 이미지, 속성 가져오는 법
2021.05.22 - [파이썬 패키지/GUI 프로그램] - [파이썬 GUI 프로그래밍] 잡플래닛 리뷰 정보 크롤링 GUI 프로그램
이번 시간에는 웹크롤링 방법(정적/동적) 두 가지 중, 동적 수집에 대해서 알아보고 간단히 실습해보겠습니다.
동적 수집이란?
동적 수집은 계속 움직이는 페이지를 다루기 위해서 selenium 패키지로 chromdriver를 제어합니다. 특정 url로 접속해서 로그인을 하거나 버튼을 클릭하는 식으로 원하는 정보가 있는 페이지까지 도달합니다. 브라우저를 직접 조작하고 브라우저가 실행될때까지 기다려주기도 해야해서 그 속도가 느리다는 특징이있습니다. 물론 사람이 하는 것보다는 빠르지만요.
웹 크롤링을 하다보면 아래와 case 같이 정적 수집이 불가능한 경우들이 많습니다.
case 1. 로그인을 해야만 접속 가능한 네이버 메일
case2. 보고 있는 위치에 따라 url이 계속 변하는 네이버 지도
case 3. 드래그를 아래로 내리면 계속 새로운 사진과 영상이 나타나는 인스타그램과 유튜브
이번 시간에는 위의 케이스들은 아니지만, 지난 시간 배운 정적 수집과 비교를 위해 페이지 버튼을 조작해서 네이버 뉴스 기사 제목 10개를 크롤링 하는 것을 하면서 방법을 익혀보겠습니다.
위에서 언급했듯이 selenium 패키지를 다루기 위해서는 크롬 드라이버가 설치되어 있어야하니, 아래의 글을 참고하셔서 설치해주세요.
2021.03.23 - [파이썬 패키지/웹크롤링] - [코딩유치원] 크롬드라이버 크롬 버전에 맞춰서 설치하는법
쉬운 이해를 위해서 코드를 끊어서 설명드려보겠습니다.
1단계. Selenium 패키지로 네이버에 접속하기
#step1.관련 패키지 import
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
#step2.검색할 키워드 입력
query = input('검색할 키워드를 입력하세요: ')
#step3.크롬드라이버로 원하는 url로 접속
url = 'https://www.naver.com/'
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
먼저 관련 패키지를 import 해야합니다. 이번 예에서는 세 번의 import가 있는데요.
앞의 두 개는 selenium 패키지에서 크롬드라이버를 제어하고, 크롬드라이버에서 원하는 키를 입력할 수 있는 모듈을 import하는 것입니다.
마지막 time은 크롬드라이버가 실행되고 페이지 이동하는 시간을 충분히 기다리기 위해서 사용하는 패키지입니다.
다음으로 query로 이름지은 변수에 사용자가 원하는 키워드를 입력받아서 대입하는 코드를 두었습니다. 사용자가 터미널을 통해서 input을 입력하지 않으면 프로그램이 진행되지 않으니 주의하세요.
그 다음엔 webdriver.Chrome( ) 함수를 이용해 크롬드라이버 자동 다운로드 및 실행 후, get( ) 함수를 이용해 원하는 url로 접속해줍니다. 이때 앞서 말했듯이 실행되기 까지의 시간을 벌어주기 위해서 time 패키지의 sleep함수를 써서 3초간 기다려줍니다.
2단계. Selenium 패키지로 원하는 페이지까지 이동하기
#step4.검색창에 키워드 입력 후 엔터
search_box = driver.find_element(By.ID, "query")
search_box.send_keys(query)
search_box.send_keys(Keys.RETURN)
time.sleep(3)
#step5.뉴스 탭 클릭
driver.find_element(By.XPATH, '//*[@id="lnb"]/div[1]/div/ul/li[2]/a').click()
time.sleep(2)
위의 코드를 한줄씩 설명하면 다음과 같습니다.
1. 네이버창의 검색창을 찾습니다. (검색 창은 id인 query를 이용해서 찾아주었습니다.)

[여기서 잠깐!]
driver은 실행 중인 Chrome Driver(정확히는 활성화 된 현재 탭)를 뜻하며, driver.find_element는 현재 탭에 출력된 HTML에서 요소를 찾겠다는 의미로 이해하시면 됩니다.
무엇을 찾겠다는 내용이 괄호 안에 쓰여지게 됩니다.괄호 안에 들어갈 수 있는 내용은 아래와 같으며, 주로 사용하는 로케이터는 TAG_NAME, ID, CLASS_NAME, CSS_SELECTOR, 그리고 XPATH 정도 입니다.

2. 아까 입력주었던 검색어를 검색창에 입력합니다.
3. 엔터 후 3초 기다립니다.
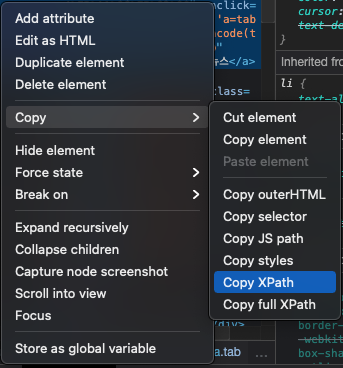
4. 검색결과(현재 통합 탭 클릭 상태)에서 뉴스 탭을 클릭합니다. 아래에서 보듯이 탭은 여러개가 있는데다가 모두 같은 class명을 사용해서 하나만 콕 집을 수 있는 xpath 방식을 사용해야합니다.

xpath를 찾으려면 아래와 같이 해당 html 부분을 우클릭하여 Copy XPath를 클릭해주면 됩니다. 그대로 VS CODE의 코딩창에 붙여넣기(Ctrl+V) 해주면 //*[@id="lnb"]/div[1]/div/ul/li[2]/a 이렇게 나오는 것을 확인 할 수 있습니다. 이걸 driver.find_element_by_xpath( )의 괄호 안에 넣어주면 됩니다. 여기서 주의할 점은 따옴표(' ')안에 넣어주어야 한다는 것입니다. xpath를 잘 보시면 쌍따옴표(" ")가 들어가 있기 때문입니다. (기초문법 강의 참고)
5. 2초 기다린다.
3단계. Selenium 패키지로 원하는 정보 수집하기
이제 원하는 정보(원하는 키워드의 뉴스 기사 10개)가 있는 페이지로 이동 완료한 상태입니다. 여기서 원하는 정보(기사 제목)를 가져오는 방법에 대해서 알아보겠습니다.
#step5.검색 결과 페이지에서 selenium 패키지로 수집해보기
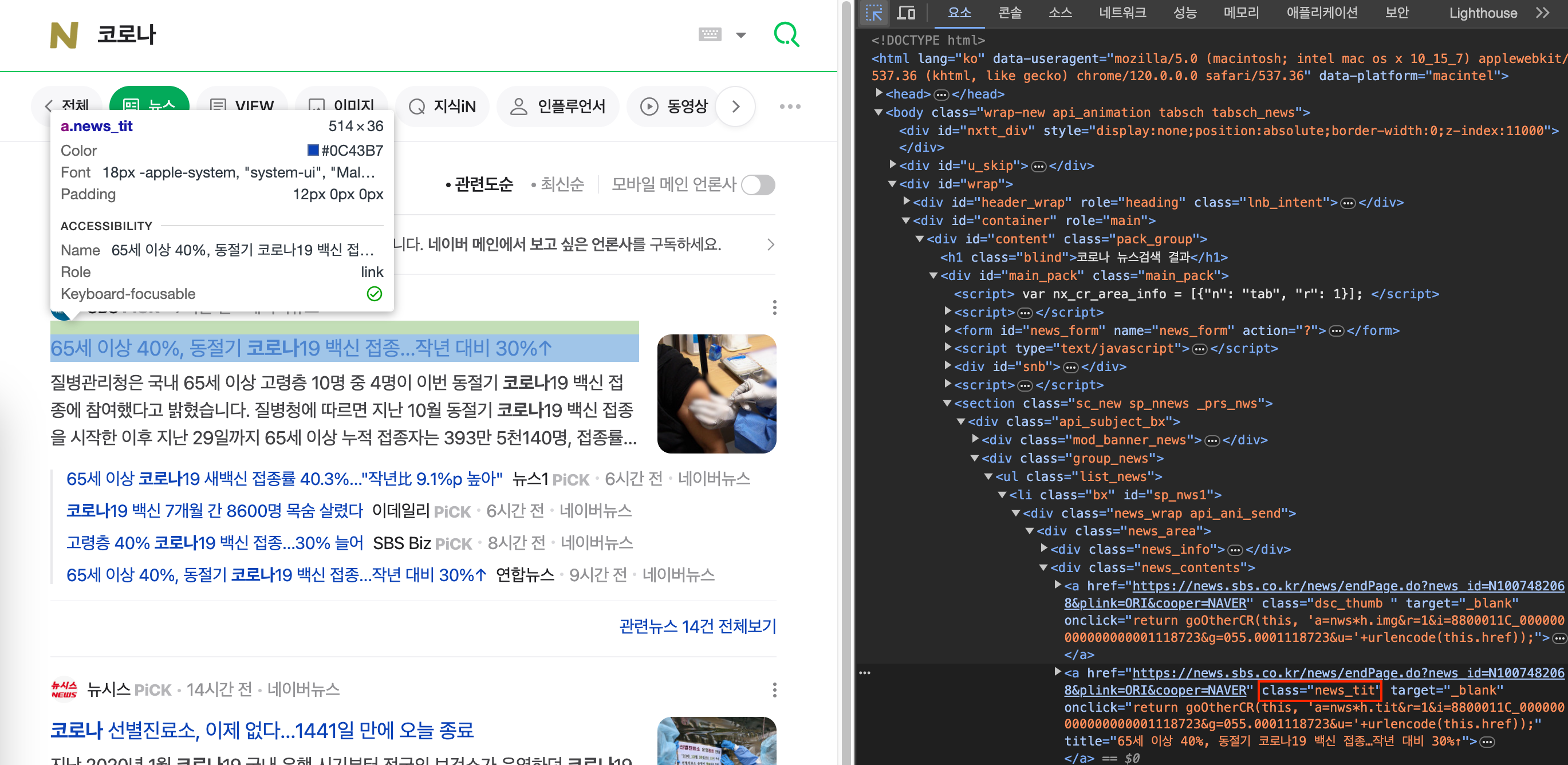
news_titles = driver.find_elements(By.CLASS_NAME, "news_tit")
for i in news_titles:
title = i.text
print(title)
이번에는 By.CLASS_NAME 로케이터를 이용해서 뉴스 제목을 가져와보았습니다.
만약 100개의 기사를 수집하고 싶다면, for문을 이용해 10번 반복하면서, 다음페이지로 넘어가는 버튼을 click() 함수로 조작하면 되겠죠?
이 부분은 직접 실습해보시길 추천드립니다.
오늘도 공부하시느라 고생많으셨습니다~