안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

<데이터 분석 관련 글>
2021.07.21 - [파이썬 패키지/데이터분석] - [코딩유치원] 비전공자도 쉽게 이해하는 데이터 분석 프로세스 (ft. 수집, EDA, 전처리, 모델링)
2021.04.12 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 1편. 데이터는 금이다 (feat.데이터 관련 직업 소개)
2021.04.13 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 2편. 데이터 분석을 위한 준비 (Jupyter Notebook 설치 및 사용법)
2021.04.14 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 3편. 데이터 분석 필수 패키지, 판다스! (feat. 10 minutes to pandas)
2021.04.15 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 4편. 데이터 분석을 위한 데이터 다운로드 받기 (feat.공공데이터포털)
2021.04.17 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 6편. 데이터 분석에서 결측치란? (feat. 주피터 노트북 Pandas 관련 함수)
2021.04.18 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 7편. 원하는 이름의 열 & 특정 문자열을 포함한 데이터 인덱싱하기
2021.07.24 - [분류 전체보기] - [파이썬 데이터 분석] 9편. 데이터 시각화 맛보기(ft. 15~20년 전국 민간아파트 분양가 데이터)
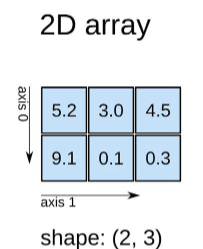
이번시간에는 데이터 분석할 때 데이터 프레임을 다양한 형태로 변형시켜서 볼 수 있는 함수인 pivot-table과 groupby에 대해서 배워보겠습니다.
피벗 테이블 (pivot-table)
먼저 피벗 테이블에 대해서 알아보겠습니다.
엑셀을 좀 아시는 분이라면 한 번쯤 들어보셨을 피벗 테이블과 같은 개념입니다. 피벗 테이블을 사용하면 데이터 프레임을 재구성해서 다른 인사이트를 얻을 수 있습니다.
글로 설명하기가 쉽지 않아서 바로 실제 예제로 설명드릴게요! 예제는 지난 시간에 전처리했던 데이터를 사용하겠습니다.
오늘도 역시 가장 먼저 할 일은 사용할 패키지들을 불러오는 것이겠죠?
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
데이터 불러오기
csv 파일을 받으셨다면 판다스로 csv 파일을 불러와주세요.
해당 코드는 csv 파일과 ipynb 파일이 동일한 폴더에 위치하여야 정상 작동합니다.
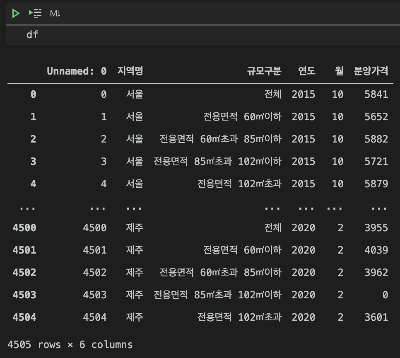
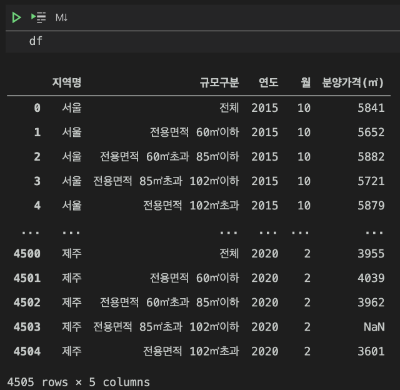
df = pd.read_csv("15~20년 전국 민간아파트 평당 분양가격.csv")
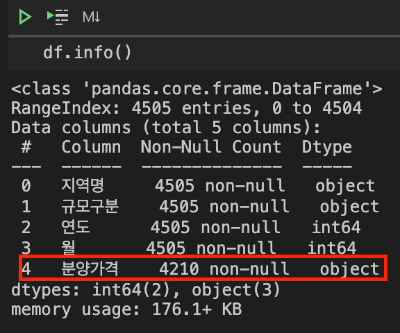
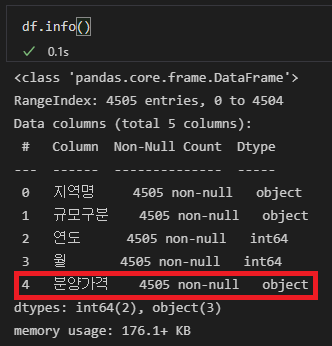
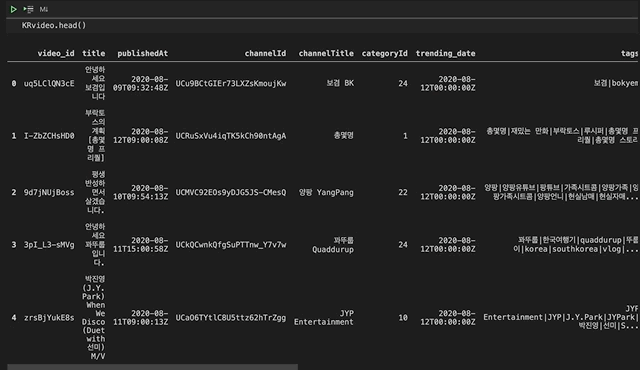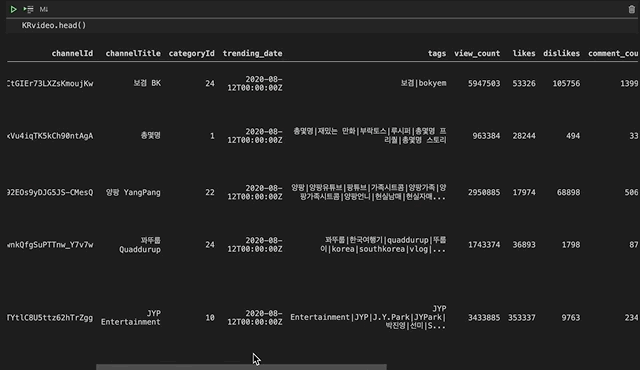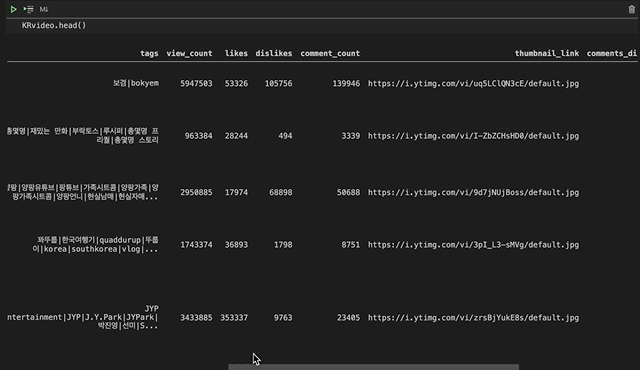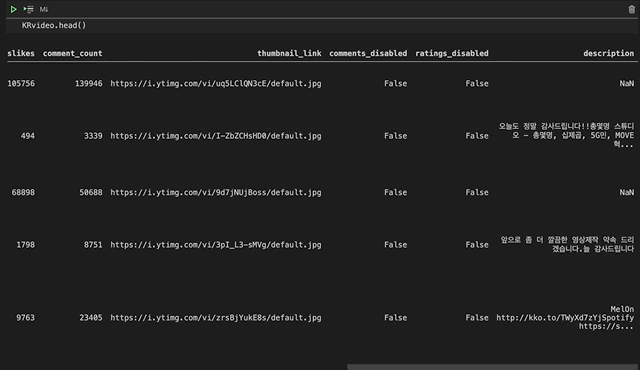
데이더가 어떻게 생겼는지 살펴보겠습니다.
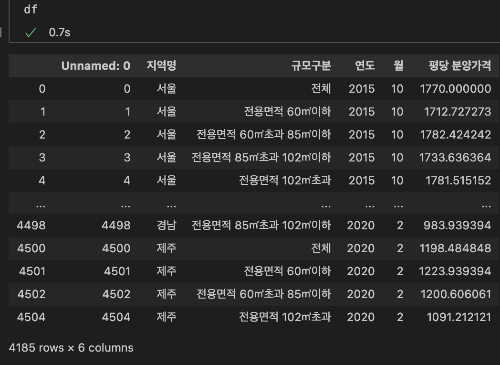
음 예전에 전처리를 하다가 저도 모르는 사이에 Unnamed: 0이라는 열이 생겼네요. 필요없는 열이라서 살포시 지워주고 넘어가겠습니다.
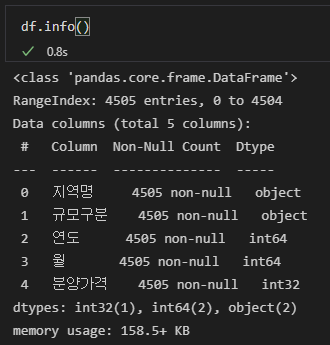
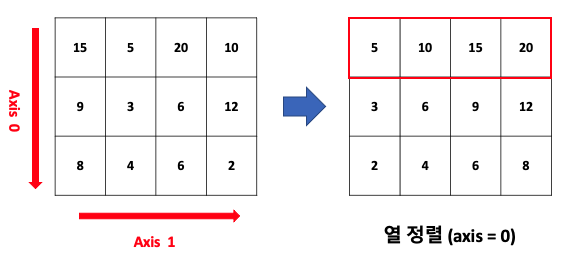
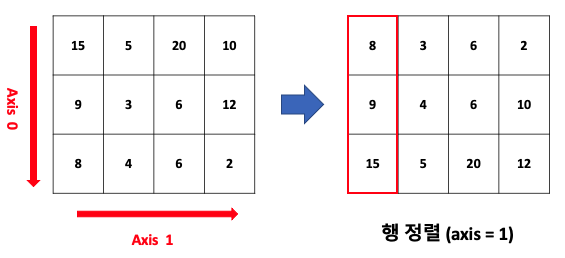
# 열 제거 시엔 '열이름'과 axis=1 / 행 제거 시엔 인덱스 번호와 axis=0
df = df.drop(['Unnamed: 0'], axis=1)
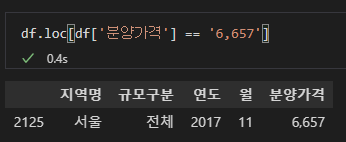
결과 확인 없이 바로 피벗 테이블 함수를 적용해보겠습니다.
# 기본적으로 평균값 출력
pd.pivot_table(df, index='지역명', columns='연도', values='평당 분양가격')
결과를 보시면 index에 입력한 '지역명'이 행을 이루고, columns에 입력한 '연도'가 열을 이루고 있습니다.
그리고 표를 채우고 있는 데이터들은 values에 입력한 '평당 분양가격'으로 이루어져 있습니다.
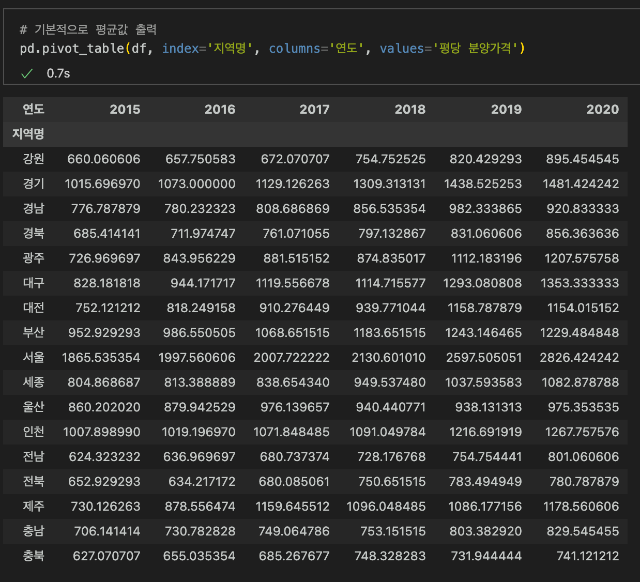
여기서 알아두면 좋은 것은 데이터 프레임을 채우고 있는 데이터들이 평균값이라는 것입니다.
만약 aggfunc 파라미터에 아래와 같은 값들을 넣어주면 다양한 결과를 얻을 수 있습니다. 참고로 np는 numpy의 약자입니다.
1) np.sum - 합계
2) np.mean - 평균
3) np.median - 중위값
4) np.var - 분산
5) np.std - 표준편차
6) np.min - 최소값
7) np.max - 최대값
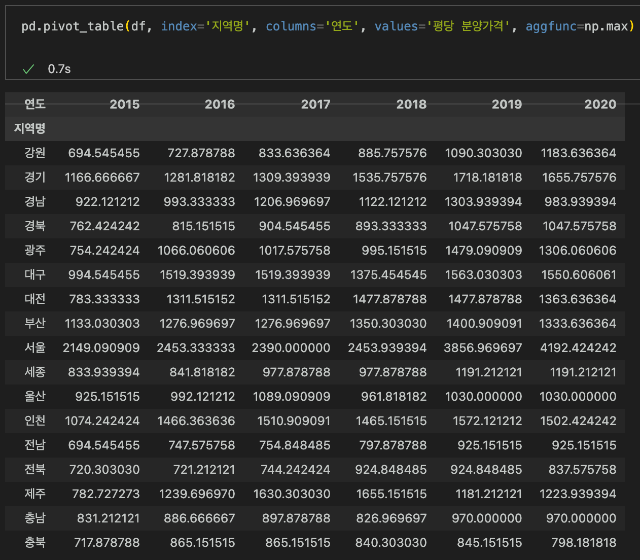
#aggfunc 옵션에 np.max를 입력하여 최대값 데이터를 출력
pd.pivot_table(df, index='지역명', columns='연도', values='평당 분양가격', aggfunc=np.max)
와.. 2020년에 서울에서 가장 비싼 분양가는 평당 약 4190만원이네요..!
groupby
groupby( ) 함수는 괄호( )안에 입력한 '컬럼명'의 데이터들을 같은 것 끼리 묶어주는 역할을 합니다.
가장 기본적인 groupby 함수 사용법은 다음과 같습니다.
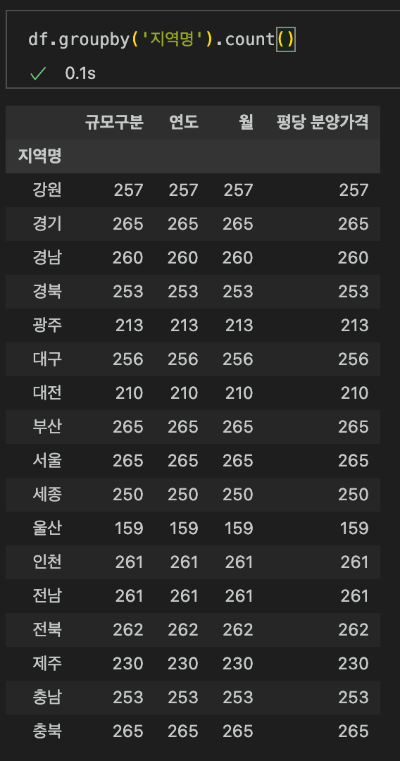
df.groupby('지역명').count()
데이터들을 '지역명'끼리 묶어서 행을 구성하고 count( ) 함수로 데이터 갯수들을 출력했습니다.
pivot-table과 비슷하게 아래와 같은 함수들을 사용해서 다양한 통계값들을 얻을 수 있습니다.
1) count() - 갯수
2) sum() - 합계
3) median() - 중위값
4) mean() - 평균
5) var() - 분산
6) std() - 표준편차
7) min() - 최소값
8) max() - 최대값
아래와 같이 원하는 열의 데이터만 출력해줄 수도 있습니다.
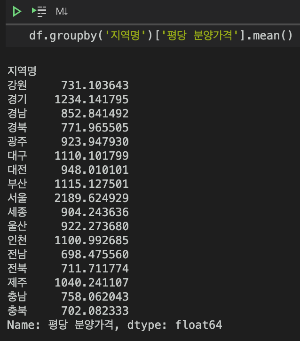
df.groupby('지역명')['평당 분양가격'].median()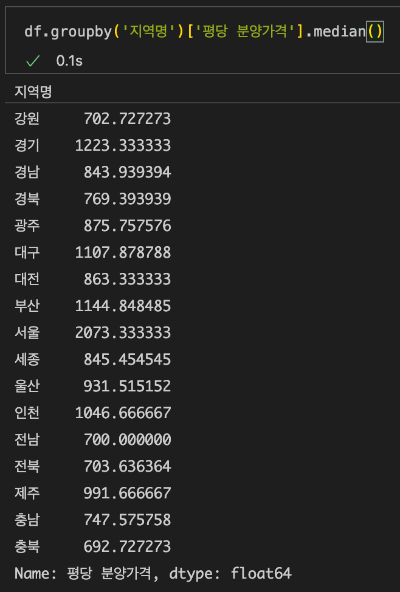
Multi-index
마지막으로 알려드릴 내용은 multi-index에 대한 내용입니다. 새로운 함수를 사용하는 것은 아니고, groupby를 사용합니다.
말로는 설명하기가 어려워 예제를 보면서 설명드리겠습니다.
df.groupby(['지역명','연도'])[['평당 분양가격']].mean()
아까 배웠던 groupby( ) 함수에는 '컬럼명'을 하나만 넣어줬다면 이번에는 ['컬러명1', '컬럼명2'] 처럼 대괄호 안에 두 가지 컬럼명을 넣어주었습니다. 참고로 순서도 중요합니다.
참고로 [['평당 분양가격']]과 같이 대괄호를 두 번 사용해준 이유는 결과를 시리즈가 아닌 데이터 프레임 형태로 보기 위함입니다. 대괄호를 하나만 써서 시리즈 형태로 출력하면 결과가 좀 덜 예쁘다랄까요?
이번 시간에 알려드릴 내용은 여기까지입니다.
열이름(컬럼명)을 바꿔가시면서 연습해보시면 확실히 pivot-table과 groupby를 마스터 하실 수 있을거예요.
오늘도 코딩유치원을 찾아주신 여러분들께 감사드립니다.
<참고 자료>
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online_패스트 캠퍼스 유료강의
'파이썬 패키지 > 데이터분석' 카테고리의 다른 글
| [#Shorts] 데이터 분석은 왜 하며, 산업별로 어떻게 활용될까요? (1) | 2022.02.03 |
|---|---|
| [파이썬 데이터 분석] 11편. Pandas hist 함수로 한눈에 데이터 분포 파악하기 (ft. 국민건강보험공단_건강검진정보) (0) | 2021.08.05 |
| [파이썬 데이터 분석] 9편. 데이터 시각화 맛보기(ft. 15~20년 전국 민간아파트 분양가 데이터) (0) | 2021.07.24 |
| [파이썬 데이터 분석] 8편. 전처리 지옥 맛보기 (ft. loc[ ] 제대로 이해하기) (0) | 2021.07.22 |
| [코딩유치원] 비전공자도 쉽게 이해하는 데이터 분석 프로세스 (ft. 수집, EDA, 전처리, 모델링) (0) | 2021.07.21 |