안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

<데이터 분석 관련 글>
2021.07.21 - [파이썬 패키지/데이터분석] - [코딩유치원] 비전공자도 쉽게 이해하는 데이터 분석 프로세스 (ft. 수집, EDA, 전처리, 모델링)
2021.04.12 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 1편. 데이터는 금이다 (feat.데이터 관련 직업 소개)
2021.04.13 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 2편. 데이터 분석을 위한 준비 (Jupyter Notebook 설치 및 사용법)
2021.04.14 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 3편. 데이터 분석 필수 패키지, 판다스! (feat. 10 minutes to pandas)
2021.04.15 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 4편. 데이터 분석을 위한 데이터 다운로드 받기 (feat.공공데이터포털)
2021.04.17 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 6편. 데이터 분석에서 결측치란? (feat. 주피터 노트북 Pandas 관련 함수)
2021.04.18 - [파이썬 패키지/데이터분석] - [파이썬 데이터 분석] 7편. 원하는 이름의 열 & 특정 문자열을 포함한 데이터 인덱싱하기
오늘은 데이터 분석가가 가장 싫어하지만, 많은 시간을 할애한다는 데이터 전처리를 맛보기로 체험해보는 시간을 가져보겠습니다.
하시면서 ValueError를 정말 많이 보시게 될텐데요. 에러가 출력되더라도 정상적인 것이니 당황하지 마시고 다음 코드로 넘어가시면 되겠습니다.
참고로 오늘도 데이터 분석은 VScode에서 Jupyter Notebook을 실행하여 진행하였습니다. 혹시 VScode와 주피터 노트북이 깔려있지 않으신분들은 '개발환경 구축' 목록을 클릭하셔서 관련 글들을 읽으시는 것을 추천드립니다.
데이터 불러오기
오늘 사용할 데이터는 공공데이터 포털에서 다운로드 받은 '민간 아파트 가격 동향' 데이터 셋입니다.
해당 코드를 실행하면 데이터 셋이 불어와지니 따로 다운로드 받으실 필요는 없습니다.
# 데이터 프레임 가져오기
df = pd.read_csv('https://bit.ly/ds-house-price')
# 데이터 프레임 출력
df
df를 출력해보면 아래와 같이 나옵니다.

열 이름 중에 '분양가격(㎡)'은 (㎡)이 코딩하면서 입력하기 어려우니 '분양가격'으로 바꾸어 주겠습니다. (글이 길어질 듯 하여 결과는 생략)
# 열 이름 바꾸는 법
df = df.rename(columns={'분양가격(㎡)': '분양가격'})
그리고 해당 데이터들은 제곱미터당 가격이므로 우리에게 익숙한 평당 가격으로 바꾸어 주려면 3.3으로 나누어서 생각하시면 됩니다.
가장 위에 위치한 2015년 10월의 평당 분양가격은 5841/3.3해서 1770만원이겠네요. 요즘 같으면 상상도 못할 낮은 가격이네요!
데이터 Overview
데이터를 전체적으로 바라보기 위해서 아래와 같은 함수를 사용해봅시다.
# 데이터 열 이름, 행 갯수, 각 열의 데이터 타입, 전체 용량 등등
df.info()

위와 같이 결과가 출력될텐데요. 여기서 주목하실 부분은 2가지 입니다.
1) 다른 열들과 다르게 분양가격에는 null이 존재
- 전체 4505개의 데이터 중 non-null 값이 4210개 (null 값 295개)
2) 데이터 타입이 정수(int)나 실수(float)가 아닌 문자열(object)
자, 이 점을 인지한채로 다음 단계로 넘어가 보겠습니다.
데이터 전처리
아마 데이터 분석가가 해당 데이터 셋을 사용하는 이유는 민간 아파트의 분양가 동향을 파악하기 위함일 것입니다.
언뜻 생각하기에 분양가에 수식이라도 걸려면 데이터 타입이 문자열이 아닌 정수나 실수여야 겠죠?
그래서 '분양가격'의 데이터 타입을 int로 바꾸어 줘보겠습니다. 지금부터 에러가 시작되니 놀라지마세요.
# 분양가격 컬럼(열)의 데이터 타입을 int로 바꿈
df['분양가격'].astype(int)
쭉 에러가 길게 나올텐데 가장 아래를 보시면 이런 문구가 있을 것입니다.
ValueError: invalid literal for int() with base 10: ' '
에러를 설명하자면 ' ' (참고로 빈칸 하나가 아니라 두 개)가 있어서 int로 못바꿔주겠다는 뜻입니다.
df.loc[ ] 함수를 이용해 어떤 행들이 분양가격이 '빈칸 두 개'로 입력되어 있는지 확인해봅시다.
# '분양가격' 열의 데이터들 중 ' '(빈칸 두개)로 이루어진 행만 출력
df.loc[df['분양가격'] == ' ']

분양가격에 아무것도 쓰이지 않은 것 같아보이지만 '빈칸 두 개 '가 들어가 있는 상태입니다.
<여기서 잠깐>
df.loc[ ] 함수
df.loc[Series, Column]의 형태로 자주 쓰이며, 특정 조건을 만족하는 데이터를 추출하거나 변경하고 싶을 때 매우매우 많이 사용됩니다.
첫번째 인자로는 주로 "True/False 정보를 담은 Series"가 들어가며, 두번째 인자는 입력을 하지 않거나, '특정 컬럼명'을 입력해줍니다.
만약 '특정 컬럼명'을 입력하면 해당 열의 정보만 가지는 Series를 출력하고, 입력하지 않으면 Series에서 True인 행의 모든 열 정보를 출력합니다. (위에서 사용한 코드는 '특정 컬럼명'을 입력하지 않은 것입니다)
빈칸을 0으로 바꾸기
loc[ ] 함수를 응용해서 ' ' 문자를 '0'으로 바꾸어 줍니다.
여기서 주의하셔야 될 점은 그냥 0이 아닌 문자열 '0'로 해주셔야 한다는 것입니다. 그냥 0으로 하여도 에러는 나지 않지만 나중에 숫자 0이 어느 순간 NaN 값으로 바뀌어서 계속 NaN 값이 잡초처럼 자라나거든요.
# 분양가격이 ' '인 것을 0으로 일괄 변경
df.loc[ df['분양가격'] == ' ', '분양가격'] = '0'
다시 '분양가격' 데이터 타입을 int로 바꾸기 위해 시도해보겠습니다.
df['분양가격'].astype(int)
또 에러가 출력됩니다. 이번에는 NaN 값이 있다고 하네요.
ValueError: cannot convert float NaN to integer
NaN 값을 0으로 바꾸기
Nan 값은 데이터 분석에서 너무 자주 나와서 따로 함수가 있습니다. fillna( )라는 함수로 NaN 값을 0으로 채워줍시다.
여기서도 주의하실 점은 그냥 0이 아닌 '0'이어야 한다는 것입니다! 이유는 위에서 설명드린 것과 같습니다.
# Nan 값을 fillna() 함수를 이용해 0으로 채워 줌
df['분양가격'] = df['분양가격'].fillna('0')
문제를 해결했으니 다시 또 변경을 시도해봅니다.
df['분양가격'].astype(int)ValueError: invalid literal for int() with base 10: '6,657'
에러를 살펴보니 숫자 사이에 콤마(,)가 있어서 int로 못바꿔주겠다는 뜻입니다.
콤마를 제거해 주기 전에 잠시 데이터를 확인해볼까요?
# '분양가격' 열의 데이터 중 '6,657'이 포함된 행 출력 (index 번호 포함)
df.loc[df['분양가격'] == '6,657']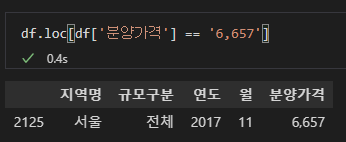
실행결과를 보시면 2125번 행에 문제가 된 데이터가 들어있는 것을 확인 하실 수 있습니다.
문자열의 특정 문자 변경하기 (replace)
문자열을 다루는 함수를 통해 콤마만 없애줘 보겠습니다.
# replace( ) 함수를 통해 ','를 ''(따옴표 사이에 아무것도 없음)로 바꾸어 줌으로써 제거
df['분양가격'] = df['분양가격'].str.replace(',', '')
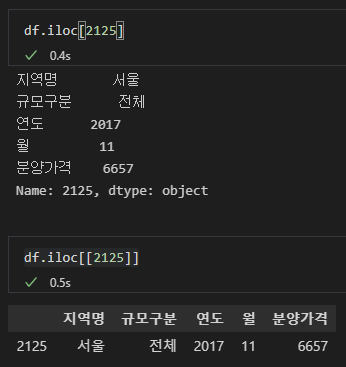
없어졌는지 확인해보겠습니다. 참고로 iloc[ ]를 loc[ ]로 바꾸어도 동일한 결과를 얻을 수 있습니다. 두 함수의 차이점은 추후 제대로 포스팅 해보겠습니다.
그리고 대괄호를 하나만 하면 시리즈 형태로 출력되고, 대괄호를 두 번 중첩하면 데이터 프레임 형태로 출력된다는 점 알려드리고 싶어서 아래와 같이 결과를 출력해봤습니다.
자 그럼 우리의 숙원 사업(?)인 astype(int)를 다시 시도해보겠습니다. 이 코드는 앞으로도 너무 많이 나오므로 '정수화'라고 명칭하겠습니다.
df['분양가격'].astype(int)
ValueError: invalid literal for int() with base 10: '-'
이번에는 누가 마이너스(-) 기호를 넣어뒀네요. 이번에도 replace 함수로 간단히 바꿔주겠습니다. (자세한 내용 생략)
df['분양가격'] = df['분양가격'].str.replace('-', '0')
'-'가 없어졌을테니 다시 한 번 정수화 시도!
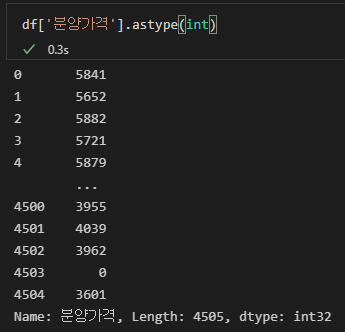
드디어 성공했습니다. 그러면 잘 바뀌었는지 볼까요?
df.info( ) 함수를 이용해서 분양가격이 object가 아닌지 다시 살펴보겠습니다.

바뀌었는데 바뀌지 않았습니다. 사실 여러분들에게 꼭 알려드리고 싶은 것이 있어서 이렇게 했답니다.
그건 바로 df['분양가격']에 변경 결과를 다시 대입해주어야 한다는 것이죠. 데이터 프레임을 다룰 때 항상 주의하셔야 할 점이랍니다.
df['분양가격'] = df['분양가격'].astype(int)
우리가 원하던 전처리인 분양가격을 문자열에서 정수로 만드는 것을 해보았습니다.
<참고 자료>
직장인을 위한 파이썬 데이터분석 올인원 패키지 Online_패스트 캠퍼스 유료강의