안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석, 머신러닝 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

<머신러닝 관련 글>
2021.07.19 - [파이썬 패키지/데이터분석] - [코딩유치원] 비전공자도 쉽게 이해할 수 있는 인공지능/머신러닝/딥러닝 개념 총정리
오늘은 머신러닝을 위한 준비물인 학습 데이터와 검증 데이터가 무엇인지, Scikit-learn 라이브러리를 이용해서 어떻게 데이터들을 나누고, 모델을 학습 시킬 수 있는지 알아보겠습니다.
참고로 오늘도 여전히 쥬피터 노트북 (저의 경우엔 VS code 위에서)을 개발환경으로 사용하였습니다.
1. Feature & Label
우선 가장 기본적인 개념인 Feature와 Label에 대해서 알아보겠습니다.
옛날 고등학생 때 배웠던 함수, y = f(x)가 기억나시나요? 함수 f(x)에 x를 입력하면, y가 나온다라는 개념입니다.
여기서 x(변수)가 feature이고 y(결과값)이 label이라고 생각하시면 됩니다.
x = feature
y = label
이때, x는 보통 학습을 위한 데이터 셋과 실제 예측을 위한 테스트 셋으로 나뉩니다.
코딩 할 때는 흔히 x_train, x_test로 표현하고, 이 값들을 모델(함수)에 넣어서 나오는 결과값을 y_train, y_test로 표현해줍니다.
2. Training set & Test set
위에서 언급했 듯, 데이터 셋은 학습을 위한 데이터 셋과 실제 예측을 위한 테스트 셋으로 나뉩니다.
1) Training set
- 컴퓨터에게 문제(feature)와 정답(label)을 알려주는 지도학습용 데이터 셋
- 마치 수학 문제와 해설 답안이 함께 제공된 시험공부하는 상황
2) Test set
- 문제(feature)만 존재
- 실제 시험에서 문제를 풀어야 하는 상황
3. 과대적합 & 과소적합
어떤 예측을 수행할 때, 아래 그래프의 가장 오른쪽(과대적합)처럼 모든 점(데이터)들을 100% 예측하는 모델을 만들었다고 가정해봅시다.
이런 경우는 너무 과하게 해당 데이터들에 적합하도록 모델이 만들어져서, 테스트 셋을 넣었을 때 예측을 빗나갈 확률이 커지게 됩니다.
마치 시험 공부를 하는데 교수님이 집어주신 문제만 달달 외우듯 공부했더니, 막상 시험 칠 때는 다른 문제가 나와서 틀리는 느낌이랄까요?
반대로 가장 왼쪽(과소적합) 그래프는 시험공부를 너무 대충한 느낌이라고 이해하시면 좋을 것 같아요.
참고로 나중에 배울 개념이지만, 전체 데이터 셋을 1회 학습한 것을 1 epoch(에포크)라고 합니다.
모델을 학습시킬 때 이 에포크를 설정해줄 수 있는데, 마치 문제집을 몇 번 반복하는지와 같은 개념입니다.
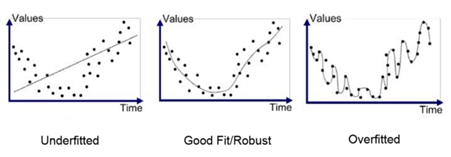
역시 적당한 것이 가장 좋은 것이라는 진리는 머신러닝에서도 적용되는 듯 합니다.
4. 검증 데이터 셋 (Validation set)

위에서 언급한 과대적합과 과소적합을 피하기 위해서 Training set의 20% 정도를 따로 분리하여 Validation set로 활용해줍니다.
(다만, 학습을 위한 코딩을 할 때엔 단순히 Training set와 Test set으로만 나누는 경우가 많습니다)
Validation set는 트레이닝 과정에서 최적점을 찾아주는 역할을 합니다.

5. Scikit-learn으로 Training set과 Validation set 나누기
이제 위에서 배운 개념을 토대로 Scikit-learn의 함수들을 이용해서 데이터를 나누어보겠습니다.
데이터 셋은 지난 시간에 다루었던 붓꽃 데이터 셋을 이용하겠습니다.

먼저 붓꽃 데이터 로드와 데이터 셋 분류와 관련된 scikit-learn 패키지를 불러와 줍니다.
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
다음으로는 dataset을 불러와서, feature와 label 변수에 필요한 데이터를 넣어줍니다.
# 붓꽃 데이터 셋
dataset = load_iris()
# feature는 붓꽃 특징 데이터, label은 붓꽃 종류 데이터
feature= dataset['data']
label = dataset['target']
이제 scikit-learn의 Train_test_split( ) 함수로 Train set과 Validation set을 나누어 주겠습니다.
x_train, x_valid, y_train, y_valid = train_test_split(feature, label, test_size=0.2, shuffle=True)
잘 나누어 졌는지 확인해볼까요?
print(feature.shape)
print(label.shape)
print(x_train.shape)
print(y_train.shape)
print(x_valid.shape)
print(y_valid.shape)
>>>
(150, 4)
(150,)
(120, 4)
(120,)
(30, 4)
(30,)
원래 150개의 데이터가 Training set 120개와 Validation set 30개로 나뉜 것을 확인 할 수 있습니다.
이번 시간엔 데이터를 나누는 것 까지해보겠습니다.
다음 시간에는 분류한 데이터로 모델을 학습시키고, 검증 데이터로 얼마나 잘 작동하는지 검증 해보도록 하겠습니다.