안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석, 머신러닝 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

[웹 크롤링 기초]
2021.03.22 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 파이썬 웹 크롤링 기초 of 기초
2021.03.23 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 크롬드라이버 크롬 버전에 맞춰서 설치하는법
2021.03.24 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 파이썬 웹 크롤링 관련 패키지 3종 총정리
2021.03.27 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 파이썬 웹 크롤링을 위한 속성 HTML, CSS 요약 정리
2021.03.28 - [파이썬 패키지/웹 크롤링] - [Python/웹 크롤링] 동적/정적 페이지 차이와 그에 따른 크롤링 방법 간단정리
[정적 웹크롤링]
2021.04.02 - [파이썬 패키지/웹 크롤링] - [Python/Requests/Beautifulsoup] 네이버 뉴스 기사 제목 크롤링을 통한 정적 수집 기초 정리
[동적 웹크롤링]
2021.04.03 - [분류 전체보기] - [코딩유치원] 네이버 뉴스 기사 제목 크롤링을 통한 동적 수집 기초 정리(selenium, beautifulsoup)
2021.06.21 - [파이썬 패키지/웹 크롤링] - [Python/Selenium] 파이썬 동적 웹크롤링 텍스트, 하이퍼링크, 이미지, 속성 가져오는 법
2021.05.22 - [파이썬 패키지/GUI 프로그램] - [파이썬 GUI 프로그래밍] 잡플래닛 리뷰 정보 크롤링 GUI 프로그램
오늘은 지난 시간 알아본 동적/정적 수집 방법 중, 정적 수집에 대해서 다루어 보려 합니다.
수집하고자 하는 웹페이지의 url을 넣어주면 항상 같은 화면을 보여주는 정적 페이지를 다룰 때 주로 사용합니다.
순서는 아래와 같습니다.
<정적 수집 순서>
1단계. 목표로 하는 웹 페이지의 html을 requests 패키지를 이용하며 받아 옴
2단계. 가져온 html 문서 전체를 beautifulsoup4 패키지를 이용하여 파싱(parsing)함
3단계. 필요한 정보만 골라서 리스트에 담음.
4단계. 리스트를 print() 함수로 출력하던가, excel이나 csv 파일에 저장.
사실 1번과 2번은 아래의 코드로 아주 간단하게 가능합니다.
1단계. requests
html 문서를 가져올 때 사용하는 패키지입니다. requests는 사용자 친화적인 문법을 사용하여 다루기 쉬우면서 안정성이 뛰어나다고 합니다. 그래서 파이썬 기본 라이브러리에 포함된 urllib 패키지보다 자주 사용됩니다.
설치 방법
VS code의 터미널창에서 아래와 같이 입력하면 됩니다. 만약 anaconda를 사용하신다면 pip 대신 conda를 입력해주셔도 됩니다.
pip install requests
사용 방법
# requests 패키지 가져오기
import requests
# 가져올 url 문자열로 입력
url = 'https://www.naver.com'
# requests의 get함수를 이용해 해당 url로 부터 html이 담긴 자료를 받아옴
response = requests.get(url)
# 우리가 얻고자 하는 html 문서가 여기에 담기게 됨
html_text = response.text
2단계. BeautifulSoup4
BeautifulSoup4 패키지는 매우 길고 정신없는 html 문서를 잘 정리되고 다루기 쉬운 형태로 만들어 원하는 것만 쏙쏙 가져올 때 사용합니다. 이 작업을 파싱(Parsing)이라고도 부릅니다.

설치 방법
마찬가지로 VS code의 터미널창에서 아래와 같이 입력하면 됩니다.
pip install beautifulsoup4
사용 방법
방금 전 Requests 패키지로 받아온 html 문서를 파싱해야하므로, 이전 코드 블록을 실행하셔야 합니다.
# BeautifulSoup 패키지 불러오기
# 주로 bs로 이름을 간단히 만들어서 사용함
from bs4 import BeautifulSoup as bs
# html을 잘 정리된 형태로 변환
html = bs(html_text, 'html.parser')
하지만 웹크롤링의 핵심은 필요한 정보의 위치와 구조를 파악해서 원하는 것만 취하는 것이 되겠습니다. 크롤링을 원하는 사이트가 생겼을 때에 능수능란하게 코딩하기 위해서는 꼭 이 스킬을 확실히 익혀두셔야 합니다.
우선 html과 css에 대해 알고 계신다는 것을 전제로 설명하도록 하겠습니다. 잘 모르시는 분들은 지난 글을 참고해주세요.
2021.03.27 - [파이썬 패키지/웹크롤링] - [코딩유치원] 파이썬 웹 크롤링을 위한 속성 HTML, CSS 요약 정리
find( ), find_all( ) 함수

find는 하나만 찾는 것, find_all은 모두 다 찾는 것입니다. 주의할 것은 find로 찾는 것이 중복이라면 가장 첫 번째 것만 가져온다는 것입니다.
괄호( ) 안에는 html의 태그(tag)나 속성(attribute)이 들어갑니다. 웹 크롤링 관련 코드를 보다보면 find 함수를 종종 사용한 경우를 보는데, 그 코드를 이해할 목적으로만 가볍게 알고 넘어가시는 것을 추천 드립니다. 왜냐하면 CSS 선택자 개념을 사용하는 select( ) 함수를 사용하는 것이 훨씬 직관적이거든요!
# 목표 태그 예)
<p class = "para">코딩유치원</p>
<div id = "zara">코딩유치원</p>
# 태그 이름으로 찾기
soup.find('p')
# 태그 속성(class)으로 찾기 - 2가지 형식
soup.find(class_='para') #이 형식을 사용할 때는 class 다음에 언더바_를 꼭 붙여주어야 한다
soup.find(attrs = {'class':'para'})
# 태그 속성(id)으로 찾기
soup.find(id='zara')
soup.find(attrs = {'id':'zara'})
# 태그 이름과 속성으로 찾기
soup.find('p', class_='para')
soup.find('div', {'id' = 'zara'})
select( ), select_one( )

select( )는 find_all( )과 같은 개념이고, select_one( )은 find( )와 같은 개념입니다. 다만, select( ) 함수는 괄호( )안에 CSS 선택자라는 것을 넣어서 원하는 정보를 찾는 것이 특징입니다. 아주 직관적이고 쉬워서 이 방법을 추천드립니다.
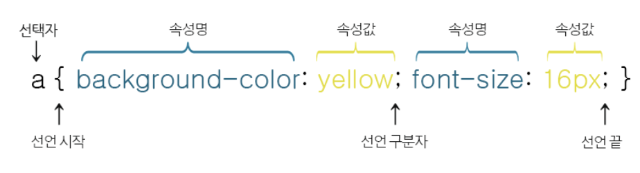
< 웹 크롤링에 자주 사용되는 CSS 선택자 >
| 분류 | 설명 | 예 |
| 태그 선택 | 특정 태그를 선택 | div -->
태그를 선택
|
| 아이디 선택 | id='속성값'인 태그를 선택 | #query --> id의 속성값이 query인 태그 선택 |
| 클래스 선택 | class='속성값'인 태그를 선택 | .title --> class의 속성값이 title인 태그 선택 |
| 태그+아이디 선택 | 특정 태그 중 id가 '속성값'인 태그를 선택 | input#query --> input 태그 중, id의 속성값이 query인 태그 선택 |
| 태그+클래스 선택 | 특정 태그 중 class가 '속성값'인 태그를 선택 | p.title --> p 태그 중, class의 속성값이 title인 태그 선택 |
<간단 예시>
# a태그의 class 속성명이 news_tit인 태그
soup.select_one('a.news_tit')
soup.select('a.news_tit')
for i in titles:
title = i.get_text() print(title)
오늘은 이 정도로 가볍게 정적 수집의 개념에 대해서 알아보고, 다음 시간에 실제로 어떻게 사용하는지 실습을 하며 배워보도록 하겠습니다.
'파이썬 패키지 > 웹 크롤링' 카테고리의 다른 글
| [코딩유치원] 네이버 뉴스 기사 제목 크롤링을 통한 동적 수집 기초 정리(selenium, beautifulsoup) (0) | 2021.04.03 |
|---|---|
| [Python/Requests/Beautifulsoup] 네이버 뉴스 기사 제목 크롤링을 통한 정적 수집 기초 정리 (7) | 2021.04.02 |
| [Python/웹 크롤링] 동적/정적 페이지 차이와 그에 따른 크롤링 방법 간단정리 (0) | 2021.03.28 |
| [Python/웹 크롤링] 파이썬 웹 크롤링을 위한 속성 HTML, CSS 요약 정리 (0) | 2021.03.27 |
| [Python/웹 크롤링] 파이썬 웹 크롤링 관련 패키지 3종 총정리 (3) | 2021.03.24 |