
반응형
안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.
코딩유치원에서는 파이썬 기초부터 사무자동화, 웹크롤링, 데이터 분석 등의 다양한 패키지까지 초보자도 알기 쉽도록 내용을 정리해 놓았습니다.
업무는 물론 투자에도 도움이 될만한 전자공시시스템(DART)나 텔레그램(Telegram) 관련 패키지도 배울 수 있으니 많은 관심 부탁드립니다.

오늘은 pandas를 공부하다가 새롭게 알게된 내용을 간단히 정리하고 공유하려고 합니다.
바로 엑셀 파일(.xlsx)을 판다스의 Data frame으로 불러올 때, 시트를 선택해서 불러오는 방법인데요.
지금까지 sheet_name을 별도로 설정 안 해줘도 잘 동작했던 이유는 sheet_name 파라미터의 기본값이 가장 첫 시트였기 때문이었습니다.
만약 한 엑셀 파일에 여러 시트가 있고, 각각의 시트를 차례대로 참조해야할 때는 오늘 내용이 도움이 될 것 같습니다.
시작하기에 앞서 테스트를 위해, 아래와 같이 시트가 2개인 엑셀 문서를 만들어 보았습니다.

1. 시트 이름으로 불러오기
먼저 시트 이름으로 "2반" 시트의 데이터를 불러와 보겠습니다.
import pandas as pd
# df = pd.read_excel("엑셀 파일 경로", sheet_name = "불러올 시트 이름")
df = pd.read_excel("Test.xlsx", sheet_name="2반")
df
<실행 결과>
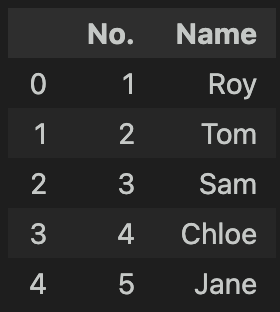
아주 잘 불러와 졌네요!
2. 시트 인덱스로 불러오기
다음으로는 시트의 인덱스를 이용해서 "2반" 시트의 데이터를 불러와 보겠습니다. 인덱스는 0부터 시작하므로 첫번째 시트가 0, 두번째 시트가 1입니다.
import pandas as pd
# df = pd.read_excel("엑셀 파일 경로", sheet_name = 불러올 시트의 인덱스)
df = pd.read_excel("Test.xlsx", sheet_name=1)
df
<실행 결과>
<참고 자료>
엑셀과 비교하며 배우는 파이썬 데이터 분석_장쥔홍 지음
반응형
'파이썬 패키지 > 데이터분석' 카테고리의 다른 글
| 데이터 분석 프로세스의 근본! 데이터 준비 과정 정리 (0) | 2022.04.25 |
|---|---|
| [#Shorts] 데이터 분석은 왜 하며, 산업별로 어떻게 활용될까요? (1) | 2022.02.03 |
| [파이썬 데이터 분석] 11편. Pandas hist 함수로 한눈에 데이터 분포 파악하기 (ft. 국민건강보험공단_건강검진정보) (0) | 2021.08.05 |
| [파이썬 데이터 분석] 10편. 데이터 프레임 배치를 내맘대로! (ft. pivot-table, groupby, multi-index) (0) | 2021.07.25 |
| [파이썬 데이터 분석] 9편. 데이터 시각화 맛보기(ft. 15~20년 전국 민간아파트 분양가 데이터) (0) | 2021.07.24 |