안녕하세요, 왕초보 코린이를 위한 코딩유치원에 오신 것을 환영합니다.

오늘은 파이썬으로 엑셀(Excel)을 다룰 때 가장 많이 사용하는 openpyxl 패키지에 대해 알아보겠습니다.
엑셀은 회사에서 업무할 때 정말 많이 사용하는 오피스 프로그램이니 알아두시면 많은 도움이 되실거라 생각합니다!
지난 시간에 배운 내용과 관련된 코드는 설명없이 넘어 갈 예정이니, 아래 내용을 모르신다면 읽고 오시는 것을 추천드립니다.
2021.05.28 - [파이썬 패키지/사무자동화] - [Python Excel] 파이썬으로 엑셀 다루기 1편_openpyxl 패키지 소개 및 시트 생성/변경
2021.05.29 - [파이썬 패키지/사무자동화] - [Python Excel] 파이썬으로 엑셀 다루기 2편_엑셀 파일 불러오기, 셀 데이터 입력/삭제 및 빈칸 추가
1. 셀 단위 가져오기
만약 B1 셀의 데이터만 가져오려면 두 가지 방법으로 가능합니다.
1) ws['B1'].value
2) ws.cell(row=1, column=2).value
참고로 .value를 붙여주지 않으면 <Cell '시트명'.B1> 와 같은 형식으로 값을 리턴합니다.
먼저 지난 시간에 배웠던대로 개별 셀에 데이터를 입력해보겠습니다.
# A4와 B1 셀에 데이터 입력
ws['A4'] = 10
ws.cell(row=1, column=2, value=15)
그럼 현재는 이런 상태이겠죠?
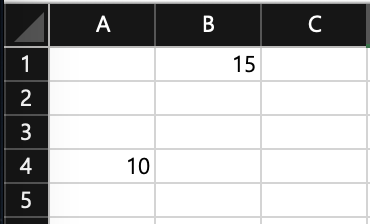
이제 이 값들을 가져와 보겠습니다.
<엑셀 포맷(알파벳+숫자)의 인덱싱 방식>
# 해당 위치의 데이터 확인
a = ws['A4']
print(a)
>>> <Cell '시트명'.A4>
b = ws['A4'].value
print(b)
>>> 10
<openpyxl 포멧(숫자, 숫자)의 인덱싱 방식>
c = ws.cell(row=1, column=2)
print(c)
>>> <Cell '시트명'.B1>
d = ws.cell(row=1, column=2).value
print(d)
>>> 10
직관적인 면에서는 'A4'와 같은 인덱싱 방법이 더 편하지만, 나중에 for문에서 row나 column을 변환시키면서 코딩해야할 때는 ws.cell( ) 방식을 사용해야만 하는 경우가 있답니다.
대략 이런 경우에 말이죠.
for x in range(1,101):
for y in range(1,101):
ws.cell(row=x, column=y)
2. 범위로 가져오기
당연히 범위로도 셀 값을 가져올 수 있습니다.
<엑셀 포맷(알파벳+숫자)의 인덱싱 방식>
# A1:B4 범위의 셀 정보 가져오기
cell_range = ws['A1:B4']
# 가져온 cell_range(이차원 튜플)의 내용 하나씩 print
for i in cell_range:
for j in i:
print(j.value)
>>>
None
15
None
None
None
None
10
None
<openpyxl 포멧(숫자, 숫자)의 인덱싱 방식>
iter_rows( ) 혹은 iter_cols( ) 함수로 행/열의 최소 최대를 입력해줌으로써 범위 내의 데이터를 가져올 수 있습니다.
아래의 코드를 보시고 두 함수가 값을 가져오는 순서 차이를 이해하고 넘어가시는 걸 추천드립니다.
(순서 차이를 위해서 cell을 print했으며, cell.value를 입력해주면 cell 안의 값을 출력합니다)
# 행 단위로 가져옴
for row in ws.iter_rows(min_row=1, max_row=4, min_col=1, max_col=2):
for cell in row:
print(cell)
>>>
<Cell 'Sheet1'.A1>
<Cell 'Sheet1'.B1>
<Cell 'Sheet1'.A2>
<Cell 'Sheet1'.B2>
<Cell 'Sheet1'.A3>
<Cell 'Sheet1'.B3>
<Cell 'Sheet1'.A4>
<Cell 'Sheet1'.B4>
# 열 단위로 가져옴
for col in ws.iter_cols(min_row=1, max_row=4, min_col=1, max_col=2):
for cell in col:
print(cell)
>>>
<Cell 'Sheet1'.A1>
<Cell 'Sheet1'.A2>
<Cell 'Sheet1'.A3>
<Cell 'Sheet1'.A4>
<Cell 'Sheet1'.B1>
<Cell 'Sheet1'.B2>
<Cell 'Sheet1'.B3>
<Cell 'Sheet1'.B4>
3. 행/열 단위 가져오기
셀을 행이나 열 단위로 가져오는 것도 가능합니다. 방금 전 위에서 배웠던 범위와 같은 방식입니다.
다만 인덱싱을 2차원이 아닌 1차원(only 행 or only 열)로 입력해주는 것만 다를 뿐이죠.
<엑셀 포맷(알파벳+숫자)의 인덱싱 방식>
# 열 하나 가져오기
col_C = ws['C']
for cell in col_C:
print(cell.value)
# 열 여러개 가져오기
col_range = ws['B:C']
for cols in col_range:
for cell in cols:
print(cell.value)
# 행 하나 가져오기 (for 문 생략_위와 동일)
row10 = ws[10]
# 행 여러개 가져오기 (for 문 생략_위와 동일)
row_range = ws[5:10]
<openpyxl 포멧(숫자, 숫자)의 인덱싱 방식>
위에서 배웠던 iter_rows( ), iter_cols( ) 함수에서 행이나 열의 max값을 생략해주면 됩니다.
여기서는 자세한 내용을 생략하고 좀 더 자주 사용할만한 개념을 소개드리겠습니다.
만약 범위를 지정하기보다 모든 행이나 열을 참조해야하는 경우는 ws.row나 ws.columns를 사용할 수 있습니다.
이 개념은 계속 데이터가 추가되어서 최대 범위가 계속 바뀔 때 유용하게 사용할 수 있답니다.
ws = wb.active
ws['C9'] = 'hello world'
tuple(ws.rows)
>>>
((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>),
(<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>),
(<Cell Sheet.A3>, <Cell Sheet.B3>, <Cell Sheet.C3>),
(<Cell Sheet.A4>, <Cell Sheet.B4>, <Cell Sheet.C4>),
(<Cell Sheet.A5>, <Cell Sheet.B5>, <Cell Sheet.C5>),
(<Cell Sheet.A6>, <Cell Sheet.B6>, <Cell Sheet.C6>),
(<Cell Sheet.A7>, <Cell Sheet.B7>, <Cell Sheet.C7>),
(<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>),
(<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>))
tuple(ws.columns)
>>>
((<Cell Sheet.A1>,
<Cell Sheet.A2>,
<Cell Sheet.A3>,
<Cell Sheet.A4>,
<Cell Sheet.A5>,
<Cell Sheet.A6>,
...
<Cell Sheet.B7>,
<Cell Sheet.B8>,
<Cell Sheet.B9>),
(<Cell Sheet.C1>,
<Cell Sheet.C2>,
<Cell Sheet.C3>,
<Cell Sheet.C4>,
<Cell Sheet.C5>,
<Cell Sheet.C6>,
<Cell Sheet.C7>,
<Cell Sheet.C8>,
<Cell Sheet.C9>))
오늘 준비한 내용은 여기까지입니다.
공부하시느라 고생 많으셨습니다.
'파이썬 패키지 > 엑셀' 카테고리의 다른 글
| [파이썬 엑셀] Openpyxl의 ws.rows와 ws.max_row의 빈칸 인식 문제 원인과 해결책 (1) | 2021.12.11 |
|---|---|
| [파이썬 엑셀] python으로 excel 다루기 5편_함수(수식) 적용, 수식 결과값을 가져오는 법(data_only = True) (1) | 2021.06.02 |
| [파이썬 엑셀] python으로 excel 다루기 4편_셀 서식 설정(맞춤, 글꼴, 테두리, 채우기, 보호) (1) | 2021.05.31 |
| [파이썬 엑셀] python으로 excel 다루기 2편_엑셀 파일 불러오기, 셀 데이터 입력/삭제 및 빈칸 추가 (0) | 2021.05.29 |
| [파이썬 엑셀] python으로 excel 다루기 1편_openpyxl 패키지 소개 및 시트 생성/변경 (8) | 2021.05.28 |